刚装好的jetson nano,需要简单的验证一下cuda nn,本文基于刚刷好的机器,进行cuda
本文主要介绍使用ubuntu上一些快捷键的配置,用作平衡多个发行版之间的使用系统下的使用习惯。如果适合大家的可以随时取走
禁用gnome-shell应用快捷启动
默认情况下,ubuntu系列的发行版会默认设置super+N来快捷启动应用程序,而本人系统使用super+N来实际切换工作区,启动应用程序的事情完全可以交给应用程序启动器。 所以第一步就需要禁用ubuntu默认预设的值
apt install dconf-editor
首先,通过排查,知道了快捷键的预设来自于gnome-shell,所以找到如下
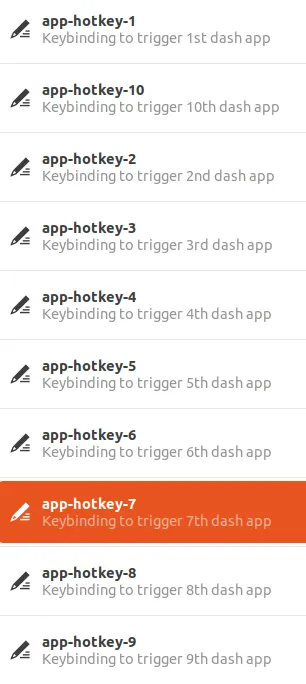
以其中一个举例,可以看到默认设置的是Super+3启动dash上的第3个应用,即文件管理器。

从左侧可以看到3对应文件夹程序

这里为了照顾自己的使用习惯,我需要先禁用super+N启动dash app的快捷键。这里修改值为 [] 即可
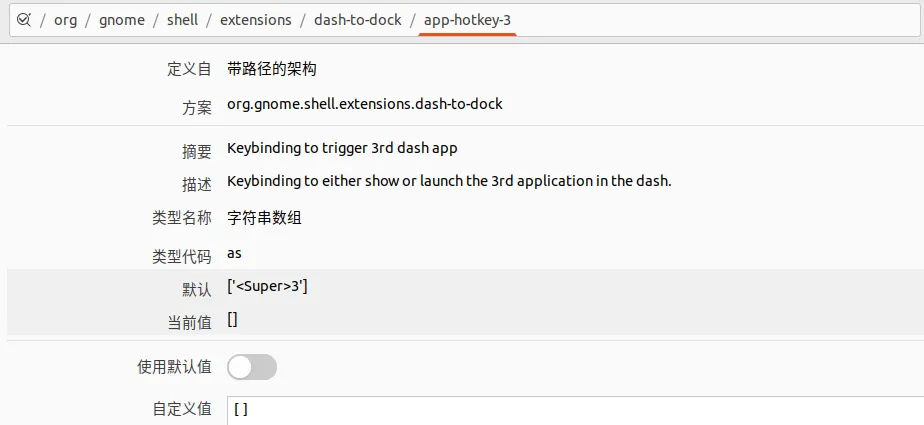
同样的,需要给app-hotkey-1到app-hotkey-10都设置成[]来禁用
设置Super+N为切换工作区
此时我们按照步骤打开如下
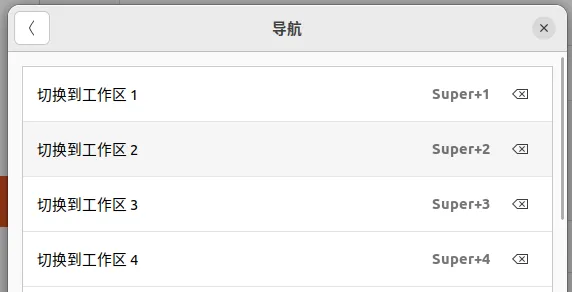
设置--->键盘--->查看及自定义按键--->导航
将切换到工作区1-4设置为Super+1/4即可,如下
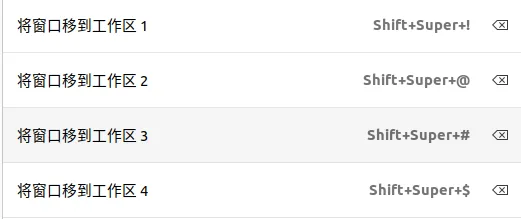
设置Super+Shift+N为将窗口移动到工作区
同样的,也要设置一个快捷键将窗口移动到工作区,如下
设置默认的工作空间
我们看到ubuntu默认设置里面预设的最大就是4个工作区,所以我们也没必要像hyprland一样无限工作区了。所以设置为4个即可。如下步骤
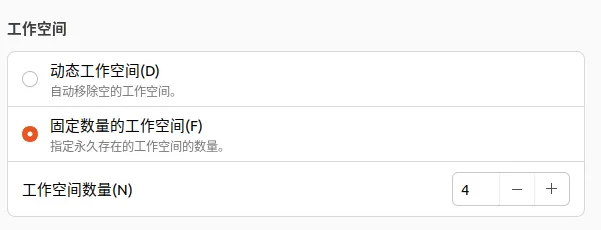
设置--->多任务--->工作空间
这里设置为固定数量的工作空间即可,值为4
命令修改
上面通过UI能够完成修改,为了方便,这里整理了命令一键修改,直接配置,如下。
# 设置super+N切换四个工作区 gsettings set org.gnome.desktop.wm.keybindings switch-to-workspace-1 "['<Super>1']" gsettings set org.gnome.desktop.wm.keybindings switch-to-workspace-2 "['<Super>2']" gsettings set org.gnome.desktop.wm.keybindings switch-to-workspace-3 "['<Super>3']" gsettings set org.gnome.desktop.wm.keybindings switch-to-workspace-4 "['<Super>4']" # 设置super+shift+N移动应用到工作区 gsettings set org.gnome.desktop.wm.keybindings move-to-workspace-1 "['<Shift><Super>exclam']" gsettings set org.gnome.desktop.wm.keybindings move-to-workspace-2 "['<Shift><Super>at']" gsettings set org.gnome.desktop.wm.keybindings move-to-workspace-3 "['<Shift><Super>numbersign']" gsettings set org.gnome.desktop.wm.keybindings move-to-workspace-4 "['<Shift><Super>dollar']" # 设置固定数量的工作空间 gsettings set org.gnome.mutter dynamic-workspaces false gsettings set org.gnome.desktop.wm.preferences num-workspaces 4 # 禁用gnome-shell预设的super+N启动应用 for i in $(seq 1 10); do gsettings set org.gnome.shell.extensions.dash-to-dock app-hotkey-$i "[]" done
总结
这样就解决了自己在切换多个发行版的时候的使用习惯不一致的问题。方便开发。
为了深入和全面的了解学习和开发嵌入式AI相关知识,我拿到了一块orin nano 开发板,接下来会在工作之余,逐渐从零开始orin系列的零基础上手技术文章,主要目的是记录这部分的知识。
本文主要是介绍orin的开箱和烧录。
开箱
官方购买的orin nano super是无任何配件的,就单纯的机器和电源。所以还需要准备如下配件
- sd卡: 我这里备了64G大小的sd卡
- ssd: 我这里备了1T的nvme ssd
- type-c线: 烧录和调试需要这根线
- 网线
- 3.3V串口: 内核及以下必备
- dp转hdmi接口: nano默认是dp接口,而我的设备都是hdmi接口
其他可能还需要camera,mic等,这些后面用到了再买吧
安装
上述配件准备并安装完成之后,就可以开始烧录安装了。
目前最新的烧录只有ubuntu2004和ubuntu2204上才能支持,所以需要给自己电脑装个ubuntu系统,我这里安装的是ubuntu2204
这里选择deb包下载,如果第一次进入,需要注册账号后下载并安装,可以获得如下文件,安装即可
dpkg -i sdkmanager_2.3.0-12617_amd64.deb apt install -f
安装完成之后,打开此程序,如下
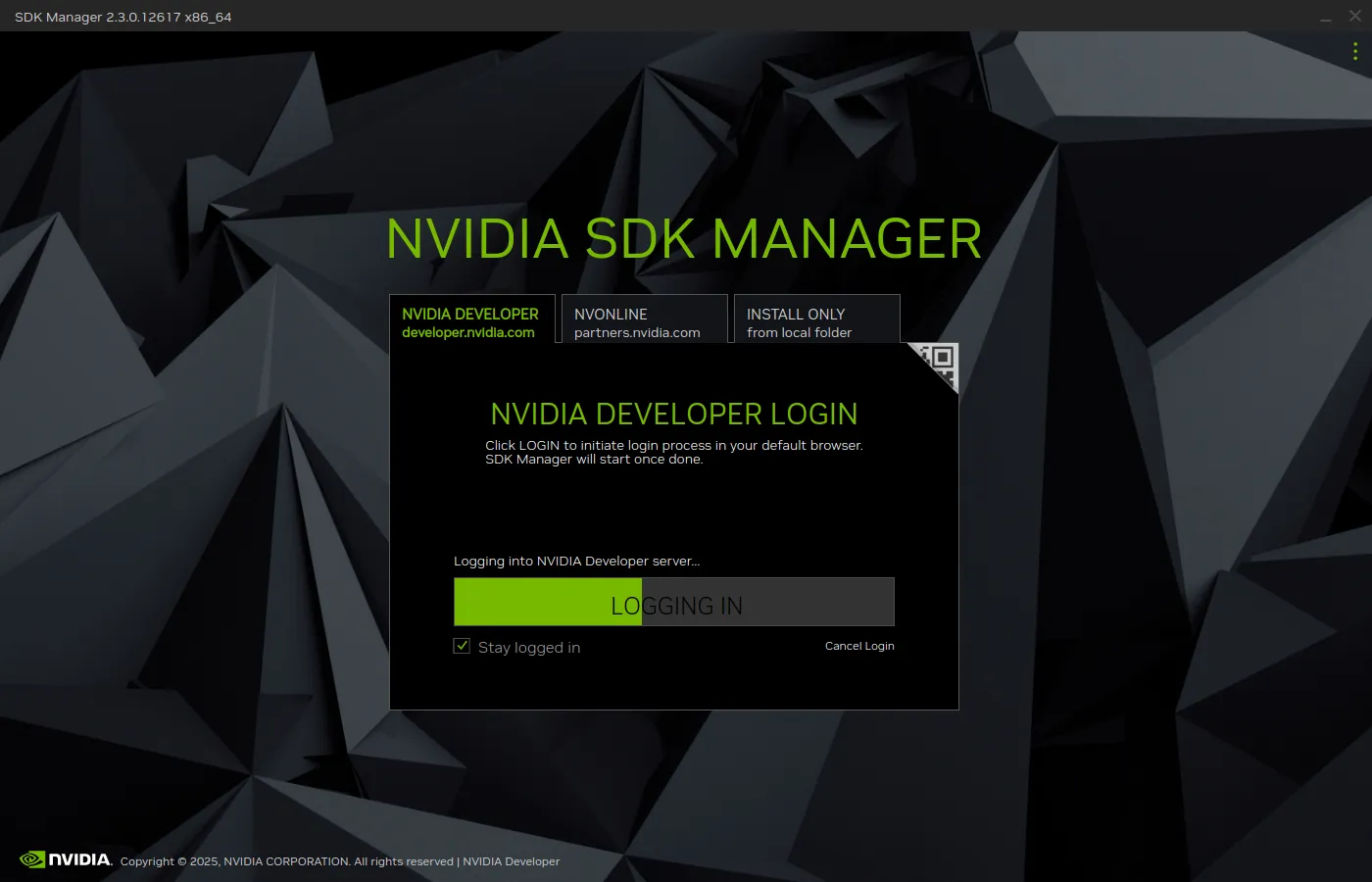
此时需要先完成账号的登陆,完成之后,如下所示
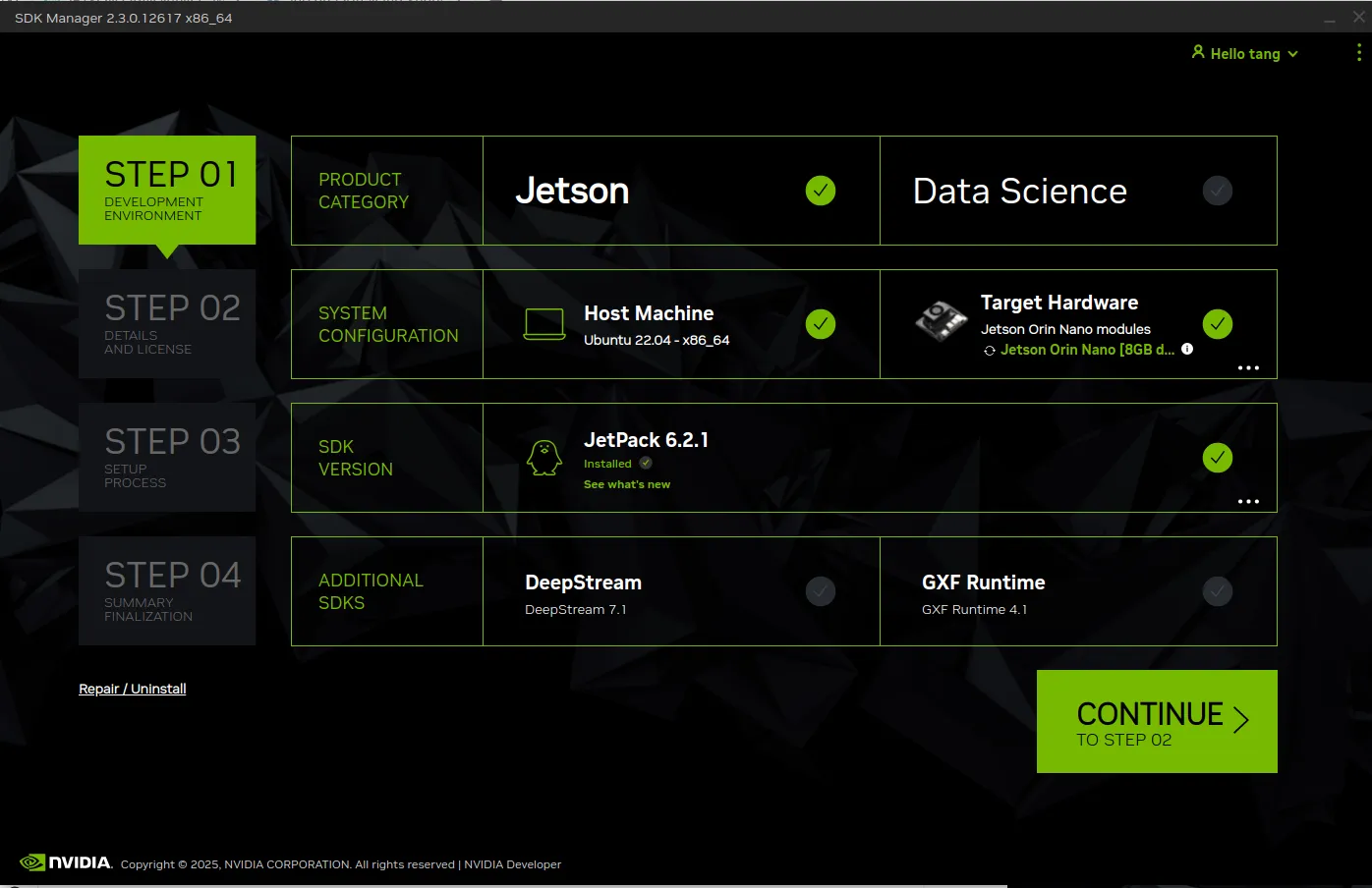
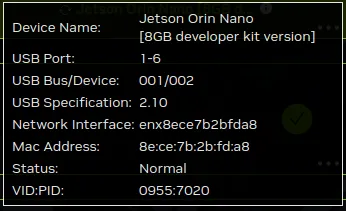
此时对于机器,需要将FC REC和GND短接(从左往右数第3,4脚),让其进入恢复模式,上电开机,即可识别设备如下

可以看到,这里选择的机器是“Jetson Orin Nano 8GB develoer kit version”, jetpack最新只能选择6.2.1。其他不用额外选择
点击continue之后,如下所示
这里仍按照默认选择,唯一额外需要做的是选中下面的接受条款
然后就是一直等待下载,下载完了之后,直接会弹出选项,提示安装位置,这里我选择为安装到nvme上即可
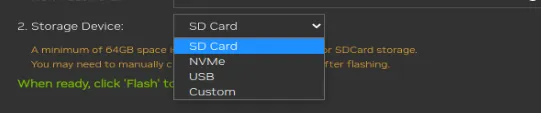
然后继续等待所有的安装完成。
值得注意的是,国内我们一定会在最后安装 docker 容器的时候安装失败,如下提示

此时我们不用关心“Nvidia Container Runtime”的失败问题,后续想办法安装。其他的选项均正常安装即可。
启动
上述安装完成之后,将FC REC和GND短接的杜邦线去掉,重新开机,等待一会儿,我们可以先从type-c的共享网卡中登录进去,如下
$ ssh kylin@192.168.55.1 kylin@192.168.55.1's password: kylin@ubuntu:~$
这里配置一下自动登录
vim /etc/gdm3/custom.conf AutomaticLoginEnable = true AutomaticLogin = kylin
换源可以参考
# 默认注释了源码镜像以提高 apt update 速度,如有需要可自行取消注释 deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ jammy main restricted universe multiverse deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ jammy main restricted universe multiverse deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ jammy-updates main restricted universe multiverse deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ jammy-updates main restricted universe multiverse deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ jammy-backports main restricted universe multiverse deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ jammy-backports main restricted universe multiverse # 以下安全更新软件源包含了官方源与镜像站配置,如有需要可自行修改注释切换 deb http://ports.ubuntu.com/ubuntu-ports/ jammy-security main restricted universe multiverse deb-src http://ports.ubuntu.com/ubuntu-ports/ jammy-security main restricted universe multiverse # 预发布软件源,不建议启用 # deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ jammy-proposed main restricted universe multiverse # deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ jammy-proposed main restricted universe multiverse
这里我们得到了调试的第一种途径,那就是通过type-c的usb_f_rndis功能,共享网卡来进行调试。
配置网卡
接下来需要利用第二种调试方式,网口。
默认情况下,nvidia提供的系统不支持netplan,所以需要安装如下
apt install netplan.io
然后我们直接修改配置如下
vim /etc/netplan/01-kylin.yaml
这里个人还是推荐静态ip还是好一点,动态ip得自己记ip。 下面配置按照静态ip配置,如下
network: version: 2 renderer: networkd ethernets: enP8p1s0: dhcp4: no addresses: - 172.25.83.92/24 routes: - to: default via: 172.25.80.1 nameservers: addresses: - 114.114.114.114
保持退出之后,应用网络即可
netplan apply
此时可以通过ssh网卡ip登录,如下
$ ssh kylin@172.25.83.92 kylin@172.25.83.92's password: kylin@ubuntu:~$
配置vnc
然后是第三种调试方式,vnc。 这里默认安装vino,如下
apt install novnc vino websockify novnc
此时默认情况下 vino 和 ubuntu 的控制面板都不允许登录,所以需要稍微配置如下
gsettings set org.gnome.Vino require-encryption false gsettings set org.gnome.Vino prompt-enabled false gsettings set org.gnome.desktop.remote-desktop.vnc enable true gsettings set org.gnome.desktop.remote-desktop.vnc auth-method 'password'
这里为了xorg默认在没插入显示器的情况下显示正常,需要配置一个dummy显示器,如下
apt install xserver-xorg-video-dummy
配置如下
vim /usr/share/X11/xorg.conf.d/99-dummy.conf Section "Device" Identifier "Configured Video Device" Driver "dummy" VideoRam 256000 EndSection Section "Monitor" Identifier "Configured Monitor" HorizSync 10.0-300 VertRefresh 10.0-200 EndSection Section "Screen" Identifier "Default Screen" Monitor "Configured Monitor" Device "Configured Video Device" DefaultDepth 24 SubSection "Display" Depth 24 Modes "1920x1080" EndSubSection EndSection
此时重启gdm 如下
systemctl restart gdm xrandr Screen 0: minimum 320 x 175, current 1920 x 1080, maximum 1920 x 1080 default connected primary 1920x1080+0+0 0mm x 0mm
我们在nano上开启vino,如下
systemctl restart vino-server --user
然后在ubuntu2204的x84机器上安装vnc client并连接,如下
apt install vinagre
此时连接即可
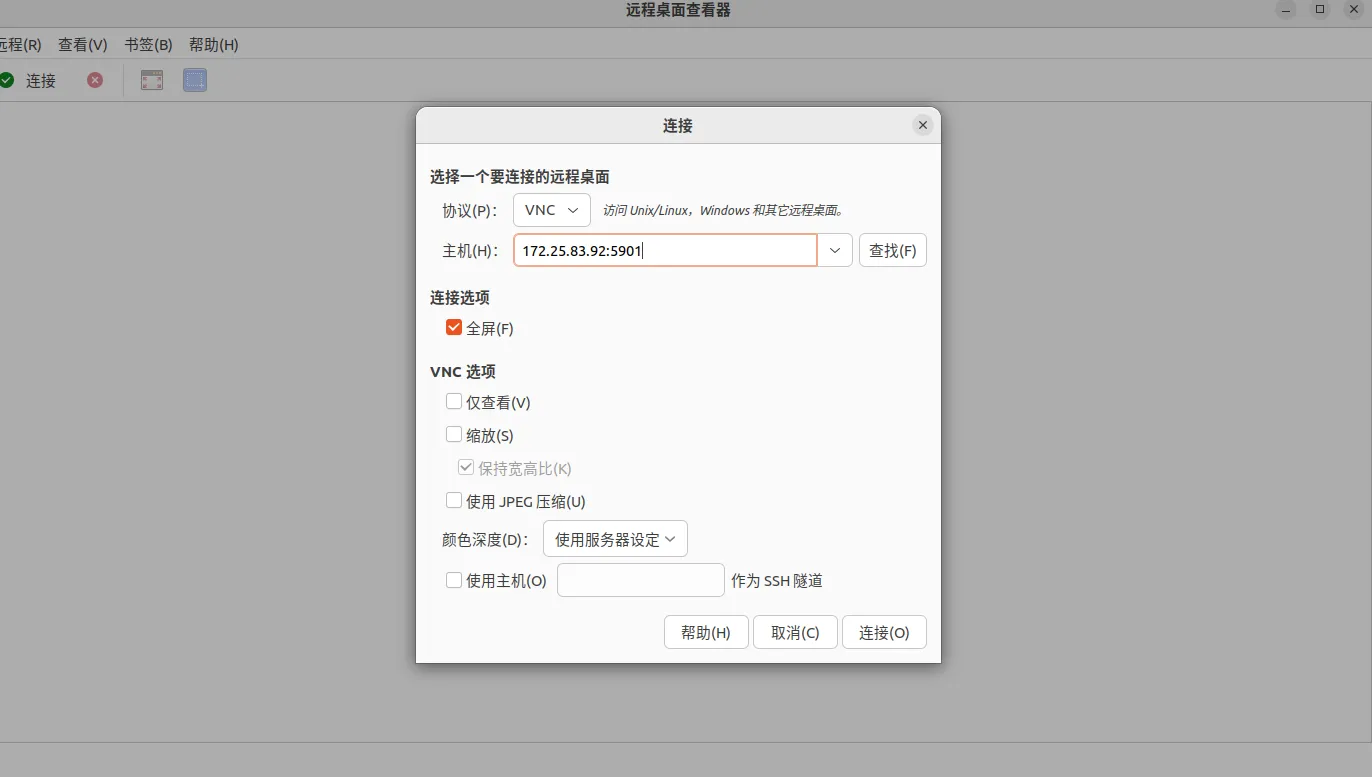
连接成功之后,如下
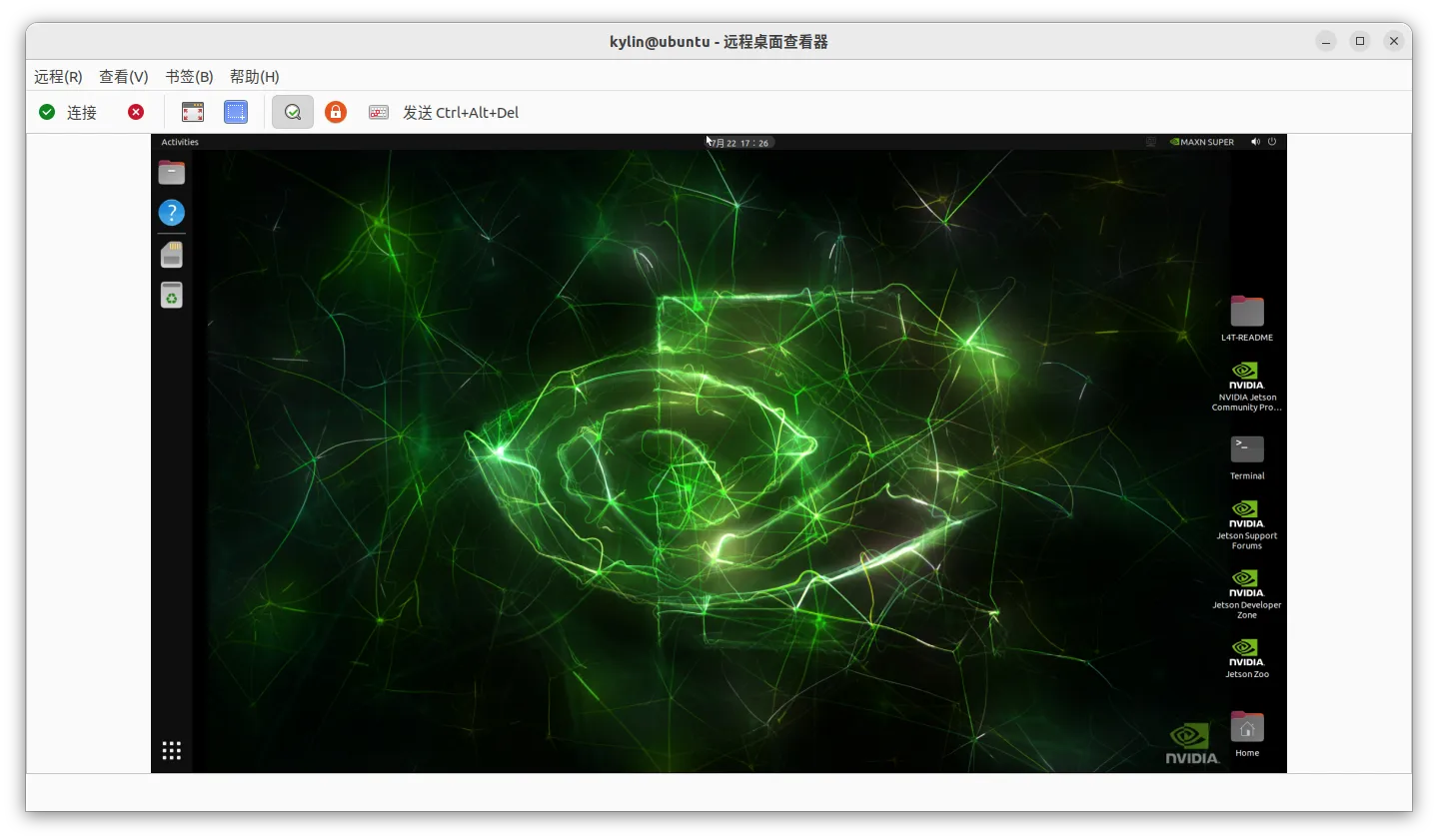
至此,nano 的vnc配置已经成功了,接下来配置novnc,vnovnc是web上的vnc,这样对我们调试来说更方便一点
配置novnc
第三种调试方式的变体,novnc。
novnc上面已经安装过了,这里我们只需要获取一下密码,然后登录即可。
密码在设置--->共享--->登录中,如下
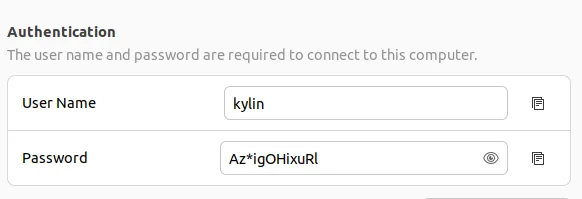
我这里获得密码是Az*igOHixuRl
此时运行novnc,如下
/usr/share/novnc/utils/launch.sh Warning: could not find self.pem Using installed websockify at /usr/bin/websockify Starting webserver and WebSockets proxy on port 6080 WebSocket server settings: - Listen on :6080 - Web server. Web root: /usr/share/novnc - No SSL/TLS support (no cert file) - proxying from :6080 to localhost:5900 Navigate to this URL: http://ubuntu:6080/vnc.html?host=ubuntu&port=6080 Press Ctrl-C to exit
然后我们通过浏览器,使用ip+6080端口登录,以防万一,我们可以确认一下配置如下,
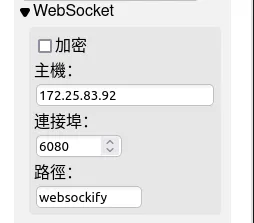
这里主机可能是主机名而不是主机IP,如ubuntu,这样如果我们没设置host,那么x86上不会识别,建议直接写ip即可。
如果上述没有任何问题,那么直接点击登录,然后输入的密码是上述查到的密码Az*igOHixuRl
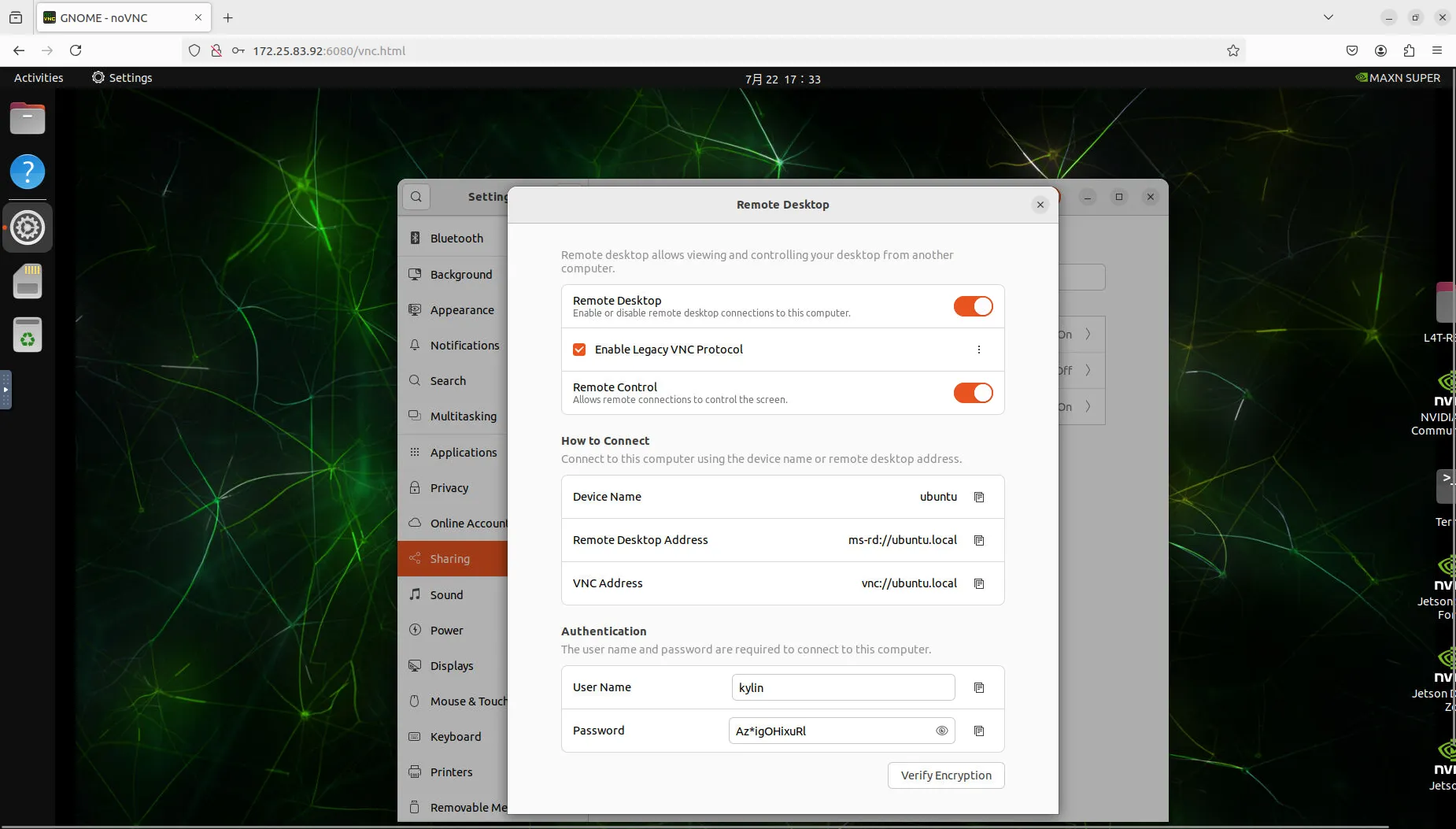
此时正常登录进入效果如下,可以看到是通过浏览器登录的设备,而不是通过vinagre程序
串口登录
为了调试设备,还要第四种方式,串口。
设备支持串口登录,所以我们首先要连接串口,默认情况下需要3.3V的串口如下接入。如下图所示

此时我们需要确认一下nano设置的串口信息,如下
$ cat /proc/cmdline root=PARTUUID=d9006785-54de-4b47-b9c7-256d03cf1c58 rw rootwait rootfstype=ext4 mminit_loglevel=4 console=ttyTCU0,115200 firmware_class.path=/etc/firmware fbcon=map:0 video=efifb:off console=tty0 nv-auto-config bl_prof_dataptr=2031616@0x271E10000 bl_prof_ro_ptr=65536@0x271E00000
可以看到,信息会从ttyTCU0上吐出来,这个TCU0就是我们刚刚连接的串口。
putty的配置如下
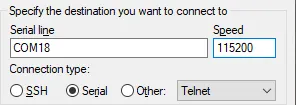
可以看到串口信息如下
Jetson System firmware version 36.4.4-gcid-41062509 date 2025-06-16T15:25:51+00: 00 ESC to enter Setup. F11 to enter Boot Manager Menu. Enter to continue boot. .......
nvcc 测试
这里装一下jetpack如下
apt install nvidia-jetpack
运行
cd /usr/local/cuda-12.6/bin # ./nvcc -V nvcc: NVIDIA (R) Cuda compiler driver Copyright (c) 2005-2024 NVIDIA Corporation Built on Wed_Aug_14_10:14:07_PDT_2024 Cuda compilation tools, release 12.6, V12.6.68 Build cuda_12.6.r12.6/compiler.34714021_0
jtop 测试

相关资料
https://developer.nvidia.com/embedded/jetson-linux-r3643
https://developer.nvidia.com/embedded/downloads
新增
值得注意的是,xorg的99-dummy.conf配置会导致默认x的渲染没有走nvidia的gpu,从而导致nvidia的一些测试用例运行失败。
如果实在要使用gpu渲染,同时不想接上显示器,鼠标键盘,希望使用vnc来调试,那么有两种办法
- 购买dp采集卡,通过usb插入电脑
- 购买dp虚拟显卡,虚拟显示器,通过novnc网页登录
我自己原来调试显示的时候买过采集卡,这就用上了。但是我还是喜欢vnc调试,所以我的方法是,通过采集卡连接,既可以像摄像头一样打开,又可以使用vnc连接,因为vnc连接很方便,我更倾向vnc连接。
