LRU算法全称是Least recently used,最近最少使用算法,他作为Linux内核页面置换算法的默认选择。原理是通过设置一个容量,LRU会选择最近最少使用的数据,并将其删除,这样能够保证了一定的容量的角度上提高系统的最大性能。
最近突然产生了一个思考,LRU算法作为缓存系统常用算法,在用户空间是否有人实现过了呢。结果发现,LRU算法可以看到在python,go,java等高级语言上实现,而在C上的单独实现全网几乎没有。
鉴于此,本文从介绍LRU算法开始,然后自己通过C语言实现了LRU算法,并进行了详细的测试,并整理文档,如有需要设计缓存系统,此代码开箱即用。
常见页面替换算法
在Linux中,所有的页面申请通过缺页异常产生,当系统没有足够空闲的页帧提供时,就需要腾挪一下页出来。那么腾挪的办法有如下几种
- OPT
- FIFO
- LRU
接下来简单介绍这些常见的替换算法
OPT
OPT也就是Optimal Page Replacement,最佳页面替换算法,其思路是永远先替换内存中最不经常使用的页面,但是如何从代码角度获得内存中最不经常使用的页面呢?
实际上,这是不现实的,因为代码层面无法准确的预计到以后哪些页面会被访问,所以无法知道哪些页面是最不经常使用的。 但是在非代码层面,例如我们在做理论分析的时候,此算法可以用于分析和衡量其他算法的实际效率。
FIFO
FIFO也就是First In First Out ,先入线程页面替换算法,其思路很简单,就是利用FIFO的特性,让所有先进入队列的页面先删除,其优点是代码设计非常简单,例如使用循环链表就能轻松实现,但是缺点是其实际应用效率并不高。
因为在实际场景中,先加入的页面,可能会被多次访问,如果使用FIFO置换页面,那么如果访问先加入的页面,那么就会频繁的换入换成,很容易造成系统颠簸。
所以在讨论页面置换的场景下,不能单纯的忽略历史数据的再次访问的情况。所以FIFO不是更好的置换算法
LRU
LRU也就是Least Recently Used,最近最少使用页面替换算法,根据刚刚讨论FIFO的缺陷,我们不能单纯的忽略历史数据,所以LRU算法应运而生
如果我们将最近访问的历史数据的优先级进行排序,那么我们就从FIFO算法转变成LRU算法,那样,每次页面替换时,默认将未被访问的先进入缓存队列的页面换出,任何被重复访问的数据都保存到优先级最高的队列头。
LRU的实现
根据上面几种算法的讨论,我们清晰的了解了LRU算法的基本原理,现在可以思考其实现思路。
- 首先,我们肯定需要通过一个循环单链表来实现FIFO的策略
- 其次,我们需要将链表尾数据挪动到链表头,所以基于循环单链表的FIFO需要修改成循环双链表,其时间复杂度是O(1)
- 再者,每次访问缓存中的页面元素时,如果从双链表中寻找,那么遍历链表复杂度是O(n),为了提高性能,可以使用hash,使其变成O(1)
- 最后,因为hash的碰撞问题,我们可以选择开发寻址法或链表法,鉴于链表法更简单,所以我使用链表法
这样基于 hash 和 doubly link list 的实现能够以最高的效率实现LRU算法,其理论是O(1),但实际是O(1)-O(n)中间,为什么呢?
因为hash存在碰撞,其碰撞情况取决于负载因子(load facotr),其计算如下load factor = capacity / slots,如果slots越大,那么hash碰撞更低,则寻找缓存页面元素的时间复杂度是O(1),如果slots为1,那么hash碰撞情况为100%,每次寻找缓存页面元素都需要遍历链表,则其时间复杂度是O(n),那么合适的设计load factor就是LRU算法的性能关键。
最终实现的LRU算法应该提供如下两个函数
- lru_get(key)
- lru_put(key,value)
get的实现
因为hash的特性,我们需要设计键值对,我们不需要完全实现一个完整意义上的hash去实现LRU,我们只需要保证key相同时,hash找到缓存value的效率是O(1)即可。 举个例子:
如果slots=10,此时key是22,那么lru_get将获取 22 % 10 ,也就是 slot=2 中的元素。又因为slot = 2 中存放的是链表,那么遍历此链表中的元素,找到key == 22 的value即可返回。
可以发现,如果slot=2 的链表有多个元素,那么证明hash还是存在碰撞,此时不是完全的O(1),但是如果slot=2只有key == 22 一个元素,那么遍历链表就是寻找其下一个节点而已,那么就是完全意义上的O(1)
如果lru_get时,key 不再任何一个槽中,则返回-1,代表lru中没有此缓存值
put的实现
关于put的实现,我们需要留意如下几个步骤
- 如果通过hash寻找到缓存,则更新value,其方法与get一致,但多了一步,就是将匹配到的节点移动到双链表头部
- 如果找不到缓存,则新建一个节点
- 因为新建了一个节点,所以需要判断链表的大小是否大于缓存的容量,如果大于,则从双链表尾部踢出一个节点
这样也就实现了LRU算法的本意,最近最少使用,最近的意思是在容量中的缓存,最少的意思是在容量中最后一个节点。组合起来就是:当新增节点时,将容量中最不经常使用的,也就是最后一个节点踢出
值得注意的是,这里虽然提到了最后一个节点是最不经常使用的,但实际上是无需使用任何排序算法的,其原因是链表的隐藏特性,对于链表的添加,都是从链表的头/尾添加,这样就已经隐式的在链表中排序了,链表最后一个节点就是最早进入链表的节点。
总结
上文比较详细的介绍了LRU算法的理论知识,可以让未对LRU算法了解的人有一个清晰的认知,本人的本意是发现Linux发行平台上,使用LRU算法的C实现例子偏少(内核外),所以抽空周末实现了C语言的LRU版本,为了介绍此版本LRU算法的目的而产生。
在实现过程中也踩了一点坑,那就是按照自己的想法,没有实现hash去解决查询的效率问题,而是通过遍历的方式寻找的key,但是后面通过网页检索回顾才发现,可以实现一个hash,将O(n)降低为0(1)。后面我又翻阅了不同开源仓库的LRU实现方法,基于开放寻找法和链表法都做了实现,但发现链表法更直接有效,所以又根据自己理解进行了完善LRU的实现。
下面是一个测试的例子
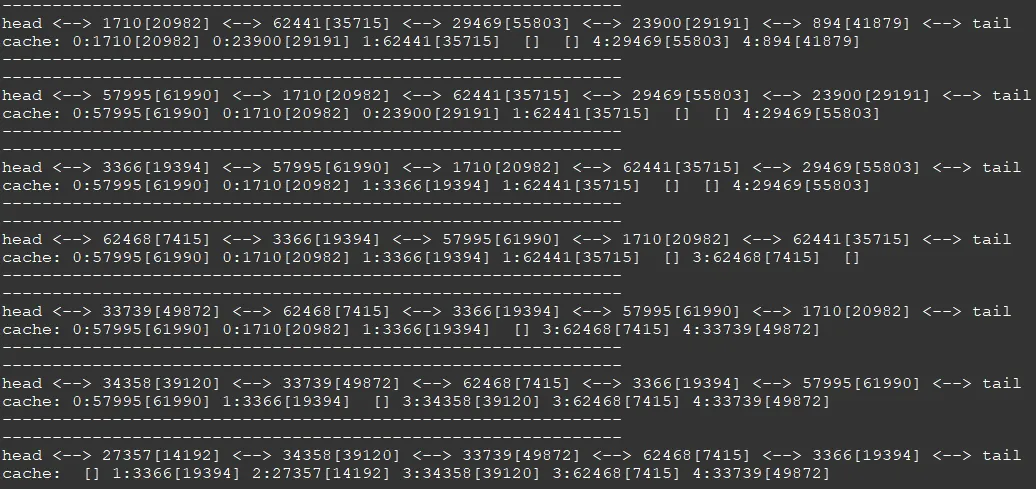
操作系统有很多问题出现在触摸事件上,而平时自己手上只有鼠标控制,突发奇想,如果我将鼠标事件虚拟成触摸,那么我复现问题,调试代码不是很方便么。
uinput
uinput是用户空间的输入设备驱动,它提供了一种功能将内核的输入设备搬到应用层来模拟。内核通过如下配置打开
CONFIG_INPUT_UINPUT=y
xlib
鉴于我们的系统目前默认是x11环境,所以我们需要使用xlib的XQueryPointer函数,此函数可以获取X下的鼠标指针位置,XQueryPointer的原型如下
Bool XQueryPointer(Display *display, Window w, Window *root_return, Window *child_return, int *root_x_return, int *root_y_return, int *win_x_return, int *win_y_return, unsigned int *mask_return);
实现
根据上面的信息,如果我们声明uinput是一个输入设备,然后通过XQueryPointer拿到鼠标在X的位置后,将其传给uinput,那么我们在系统中就白白获得了一个虚假的触摸设备。代码如下
#include <stdio.h> #include <pthread.h> #include <stdlib.h> #include <string.h> #include <time.h> #include <fcntl.h> #include <unistd.h> #include <linux/uinput.h> #include <X11/Xlib.h> void emit(int fd, int type, int code, int val) { struct input_event ie; ie.type = type; ie.code = code; ie.value = val; ie.time.tv_sec = 0; ie.time.tv_usec = 0; write(fd, &ie, sizeof(ie)); } int main(void) { struct uinput_setup usetup; struct uinput_abs_setup uabs; int fd = open("/dev/uinput", O_WRONLY | O_NONBLOCK); ioctl(fd, UI_SET_EVBIT, EV_KEY); ioctl(fd, UI_SET_KEYBIT, BTN_TOUCH); ioctl(fd, UI_SET_EVBIT, EV_REL); ioctl(fd, UI_SET_RELBIT, REL_X); ioctl(fd, UI_SET_RELBIT, REL_Y); ioctl(fd, UI_SET_EVBIT, EV_ABS); ioctl(fd, UI_SET_ABSBIT, ABS_MT_POSITION_X); ioctl(fd, UI_SET_ABSBIT, ABS_MT_POSITION_Y); ioctl(fd, UI_SET_ABSBIT, ABS_MT_SLOT); ioctl(fd, UI_SET_ABSBIT, ABS_MT_TRACKING_ID); memset(&usetup, 0, sizeof(usetup)); usetup.id.bustype = BUS_USB; usetup.id.vendor = 0x1234; usetup.id.product = 0x5678; strcpy(usetup.name, "kylin virtual touch device"); ioctl (fd, UI_SET_PROPBIT, INPUT_PROP_DIRECT); memset(&uabs, 0, sizeof(uabs)); uabs.code = ABS_MT_SLOT; uabs.absinfo.minimum = 0; uabs.absinfo.maximum = 9; ioctl(fd, UI_ABS_SETUP, &uabs); memset(&uabs, 0, sizeof(uabs)); uabs.code = ABS_MT_POSITION_X; uabs.absinfo.minimum = 0; uabs.absinfo.maximum = 1920; uabs.absinfo.resolution= 76; ioctl(fd, UI_ABS_SETUP, &uabs); memset(&uabs, 0, sizeof(uabs)); uabs.code = ABS_MT_POSITION_Y; uabs.absinfo.minimum = 0; uabs.absinfo.maximum = 1200; uabs.absinfo.resolution= 106; ioctl(fd, UI_ABS_SETUP, &uabs); ioctl(fd, UI_DEV_SETUP, &usetup); ioctl(fd, UI_DEV_CREATE); Display *display; Window root; Window child; int root_x, root_y, win_x, win_y; unsigned int mask; display = XOpenDisplay(NULL); if (display == NULL) { return 1; } root = DefaultRootWindow(display); /* * On UI_DEV_CREATE the kernel will create the device node for this * device. We are inserting a pause here so that userspace has time * to detect, initialize the new device, and can start listening to * the event, otherwise it will not notice the event we are about * to send. This pause is only needed in our example code! */ sleep(1); int mouse_fd = open("/dev/input/event4", O_RDONLY); if (mouse_fd < 0) { ioctl(fd, UI_DEV_DESTROY); close(fd); return EXIT_FAILURE; } while (1) { struct input_event ie; read(mouse_fd, &ie, sizeof(ie)); if (ie.type == EV_REL && (ie.code == REL_X || ie.code == REL_Y)) { continue; } switch (ie.code){ case BTN_LEFT: if(ie.value==1){ XQueryPointer(display, root, &root, &child, &root_x, &root_y, &win_x, &win_y, &mask); emit(fd, EV_ABS, ABS_MT_TRACKING_ID, 1); emit(fd, EV_ABS, ABS_MT_POSITION_X, root_x); emit(fd, EV_ABS, ABS_MT_POSITION_Y, root_y); emit(fd, EV_KEY, BTN_TOUCH, 1); emit(fd, EV_SYN, SYN_REPORT, 0); }else{ emit(fd, EV_ABS, ABS_MT_TRACKING_ID, -1); emit(fd, EV_KEY, BTN_TOUCH, 0); emit(fd, EV_SYN, SYN_REPORT, 0); } default: break; } } /* * Give userspace some time to read the events before we destroy the * device with UI_DEV_DESTOY. */ sleep(1); XCloseDisplay(display); ioctl(fd, UI_DEV_DESTROY); close(fd); return 0; }
值得注意的是,因为我们插入的鼠标的事件是不太确定的,所以需要提前手动查询一下,如下
先通过lsusb查看鼠标设备
# lsusb ...... Bus 001 Device 003: ID 25a7:fa61 Compx 2.4G Receiver
然后通过proc下的信息找到对应的事件
# cat /proc/bus/input/devices ...... I: Bus=0003 Vendor=25a7 Product=fa61 Version=0110 N: Name="Compx 2.4G Receiver Mouse" P: Phys=usb-fc800000.usb-1.2/input1 S: Sysfs=/devices/platform/fc800000.usb/usb1/1-1/1-1.2/1-1.2:1.1/0003:25A7:FA61.0002/input/input4 U: Uniq= H: Handlers=event4 B: PROP=0 B: EV=17 B: KEY=1f0000 0 0 0 0 B: REL=1943 B: MSC=10
此时我们知道事件是event4,那么代码填入的就是event4如下
int mouse_fd = open("/dev/input/event4", O_RDONLY);
此时编译上述代码如下
gcc mouse2touch.c -lX11 -pthread -o mouse2touch
如果我们在机器内运行,因为会XOpenDisplay,所以需要DISPLAY的环境变量设置正确,默认可以设置如下
export DISPLAY=:0
此时直接运行即可
root@kylin:~# ./mouse2touch
注意此程序是daemon进程,会while 1监听事件,如果突然退出需要检查是否有其他异常
当程序运行后,我们看到内核会有如下日志
input: kylin virtual touch device as /devices/virtual/input/input28
然后我们查看事件也能在/proc/bus/input/devices存在如下
I: Bus=0003 Vendor=1234 Product=5678 Version=0000 N: Name="kylin virtual touch device" P: Phys= S: Sysfs=/devices/virtual/input/input28 U: Uniq= H: Handlers=event18 B: PROP=2 B: EV=f B: KEY=400 0 0 0 0 0 B: REL=3 B: ABS=260800000000000
同样的Xorg也能正常识别,所以Xorg也有如下日志
tail -f /var/log/Xorg.0.log (II) event18 - kylin virtual touch device: is tagged by udev as: Touchscreen (II) event18 - kylin virtual touch device: device is a touch device
正好对应上了。此时我们点击鼠标,可以看到有触摸的特效出现
可以发现功能得到实现了,至此已经完全满足我在不需要触摸屏的前提下调试触摸的操作系统BUG了。
缺陷
上面通过编写了一个小程序,实现了鼠标模拟触摸的情况,但是还是有一些小缺点的,主要如下
- 鼠标和触摸两个事件都会触发,所以单击对系统而言是双击
- uinput的触摸事件没有TOUCH_UPDATE,所以没办法实现拖拽
- 我的代码没有去打开多个设备实现模拟多指,所以没办法调试手势问题
总结
根据上面的信息,我简单的利用了uinput来辅助调试操作系统触摸问题,稍微扩展一下,我留个疑问,有兴趣可以思考一下。
- 互联互通的鼠标流转功能,是不是uinput实现更底层,直接,和高性能呢?
双向链表是刚毕业就基于linux的实现了解过,后面因为内核的实现没办法直接搬出来用,所以自己应用开发的时候借鉴linux的实现重写了一份,这样方便自己粘贴到任意代码上。
时间长了,关于双向链表的实现很容易印象不深刻,这时候别人突然一问,让我写一个双向链表出来,我能给出思路,但是没办法完美写出来。
举个例子,我们每个人都学过关雎,里面一句"窈窕淑女,君子好逑"可谓人尽皆知,但突然某一天,有人让你背诵关雎,你会不会发懵呢?
本文基于linux内核的实现做一下分析,然后将自己的实现粘贴进来,主要目的是做一个复习。如有有喜欢我的实现的,放心拿去用好啦。
结构体
在内核中list.h实现了双向链表,其结构如下
struct list_head { struct list_head *next, *prev; };
初始化
doubly linked list的创建就是将自己指向自己。所以有如下宏
#define LIST_HEAD_INIT(name) { &(name), &(name) } #define LIST_HEAD(name) \ struct list_head name = LIST_HEAD_INIT(name)
这样传入list_head结构体就可以初始化一个doubly linked list。
内核还提供了一个函数实现INIT_LIST_HEAD来实现初始化
static inline void INIT_LIST_HEAD(struct list_head *list) { WRITE_ONCE(list->next, list); list->prev = list; }
插入
对于链表的插入需要区分头插还是尾插。那么add有两个实现 list_add和list_add_tail。内核将其头插和尾插抽象成形参传递了,如下
static inline void __list_add(struct list_head *new, struct list_head *prev, struct list_head *next)
这里如果是头插,那么组成关系如下
head ---> new ---> head->next
如果是尾插,那么组成关系如下
head->prev ---> new ---> head
所以__list_add的实现只需要关心位于new的prev和next的位置,那么list_add和list_add_tail只是不同的封装而已,考一下大家,下面哪个是list_add,哪个是list_add_tail。
__list_add(new, head, head->next); // 1 __list_add(new, head->prev, head); // 2
关于__list_add的实现就是
- 将待插入的new的prev指向prev
- 将待插入的new的next指向next
- 将原next的prev设置为new
- 将原prev的next设置为new
值得注意的是,针对prev->next使用了WRITE_ONCE,这样使得prev->next会保证赋值的有效性。 所以我们看内核实现如下
static inline void __list_add(struct list_head *new, struct list_head *prev, struct list_head *next) { next->prev = new; new->next = next; new->prev = prev; WRITE_ONCE(prev->next, new); }
内核关于list_add和list_add_tail的实现如下
static inline void list_add(struct list_head *new, struct list_head *head) { __list_add(new, head, head->next); } static inline void list_add_tail(struct list_head *new, struct list_head *head) { __list_add(new, head->prev, head); }
删除
对于删除节点而言,我们只需要知道被删除节点即可。然后如下
- 将待删除的节点的prev的next设置为待删除节点的next。修复待删除节点的prev的next
- 将待删除的节点的next的prev设置为待删除节点的prev。修复待删除节点的next的prev
对于内核而言,其实现也做了抽象。我们知道待删除节点假设是entry,那么__list_del提供两个参数,一个是prev,一个是next。这样对于删除而言就是简单的如下
- 将prev的next设置为next
- 将next的prev设置为prev
那么内核实现如下
static inline void __list_del(struct list_head * prev, struct list_head * next) { next->prev = prev; WRITE_ONCE(prev->next, next); }
当内核实现了__list_del,那么关于删除函数__list_del_entry就是简单的将形参entry拆分成entry->prev和entry->next。如下
static inline void __list_del_entry(struct list_head *entry) { __list_del(entry->prev, entry->next); }
基于上面,为了满足调试需求,内核故意对被删除的节点设置了固定的值,这样使用crash等工具就能很方便的判断问题了。如下
static inline void list_del(struct list_head *entry) { __list_del_entry(entry); entry->next = LIST_POISON1; entry->prev = LIST_POISON2; } define LIST_POISON1 ((void *) 0x100 + POISON_POINTER_DELTA) #define LIST_POISON2 ((void *) 0x122 + POISON_POINTER_DELTA) CONFIG_ILLEGAL_POINTER_VALUE=0xdead000000000000
我们组合一下上面值可以得到如下
0xdead000000000100 0xdead000000000122
我们经常使用crash的同学可以看到如下信息
list = { next = 0xdead000000000100, prev = 0xdead000000000122 }
替换
替换函数的主要思路为
- 将new的next设置为old的next
- 将new的next的prev设置为new自己
- 将new的prev设置为old的prev
- 将new的prev的next设置为new自己
也就是说先针对new自身的next,设置为old的next,同时修复原old的next的prev改变成new自己。
然后再针对new自身的prev,设置为old的prev,同时修复原old的prev的next设置为自己
所以替换的实现如下
static inline void list_replace(struct list_head *old, struct list_head *new) { new->next = old->next; new->next->prev = new; new->prev = old->prev; new->prev->next = new; }
交换
交换的目标是对entry1和entry2的内容在链表进行交换。 那么思路应该如下
- 拿到entry2的prev
- 将entry2删掉
- 将entry2替换到entry1的位置上
- 将entry1添加到entry2的prev后面
根据上面的分析,以及以上章节的代码展示,可以默写步骤如下
- 获取entry2->prev
- list_del(entry2)
- list_replace(entry1, entry2)
- list_add(entry1, entry2->prev)
但是上面可能在一种情况下出bug,那就是当entry2->prev就是entry1的时候,此时对entry2->prev的头插,就是对entry1的头插,但是list_replace已经修改了entry1的值变成实际entry2的实际值,所以entry2->prev已经不是属于这个doubly link list中了,所以我们更新为entry2。代码如下
static inline void list_swap(struct list_head *entry1, struct list_head *entry2) { struct list_head *pos = entry2->prev; list_del(entry2); list_replace(entry1, entry2); if (pos == entry1) pos = entry2; list_add(entry1, pos); }
上面如果理解不太清楚,下面我画图解释如下。最开始链表如下
---> entry1(pos) ---> entry2 ---->
当删除entry2时,如下
---> entry1(pos) ---->
当替换entry1的之后如下
---> entry2 ---->
此时我们需要完成步骤4,但是此时entry1也就是pos不在这个双向链表中了。所以我们需要强制修改pos为entry2如下
---> entry2(pos) ---->
然后调用list_add,结果如下
---> entry2(pos) ----> entry1 ---->
很明显,如果entry1不是entry2的prev,那么就无需关心此问题
移动
移动非常好理解,就是将某个元素删除后,然后通过__list_add添加,因为__list_add有两个实现,所以move有两个版本也就是list_move和list_move_tail。其实现如下
static inline void list_move(struct list_head *list, struct list_head *head) { __list_del_entry(list); list_add(list, head); } static inline void list_move_tail(struct list_head *list, struct list_head *head) { __list_del_entry(list); list_add_tail(list, head); }
拼接
关于拼接,__list_splice也做了抽象,这样便于理解,所以有三个形参如下
static inline void __list_splice(const struct list_head *list, struct list_head *prev, struct list_head *next)
这里list是待拼接的链表,而prev和next是需要拼接的位置的prev和next。
对于拼接而言,其步骤如下
- 将待拼接的next的prev设置为prev
- 将prev的next设置为待拼接的next
- 将待拼接的prev的next设置为next
- 将next的prev设置为待拼接的prev
上面需要进一步解释,这里我们因为待拼接的list是整个list,所以我们知道如下
- 待拼接的next是待拼接的第一个元素
- 待拼接的prev是待拼接的最后一个元素
- 待拼接的next的prev是第一个元素的prev,也就是原head
- 待拼接的prev的next是最后一个元素的next,也是原head
经过这样进一步的解释,再对照内核如下代码
static inline void __list_splice(const struct list_head *list, struct list_head *prev, struct list_head *next) { struct list_head *first = list->next; struct list_head *last = list->prev; first->prev = prev; prev->next = first; last->next = next; next->prev = last; }
我们可以清楚的知道了拼接的实现
entry
内核提供了list_entry实现,其实就是container_of。关于container_of这里不重复了,可以查阅文章《内核C语言结构体定位成员》
遍历
对于双向循环链表的遍历,可以分为根据next遍历,还是根据prev遍历,所以有两个变体,如下
#define list_for_each(pos, head) \ for (pos = (head)->next; pos != (head); pos = pos->next) #define list_for_each_prev(pos, head) \ for (pos = (head)->prev; pos != (head); pos = pos->prev)
安全遍历
根据遍历的代码,可以看到是通过for循环,从head处一直找next/prev,直到pos再次等于head的时候停止遍历。但是这里实际上是不安全的。也是很多代码导致崩溃的原因,本人遇到未使用安全遍历导致遍历崩溃的问题已经数十次有余了。
其原因是这个list的当前值,会在for语句里面可能被删除,例如在list_for_each的里面,会调用list_del(pos)把当前pos删掉。针对这种情况,需要引入一个临时遍历n,它保存了pos->next的值。这样安全的意思就是在遍历的过程中,可以放心的删除pos。其代码实现如下
#define list_for_each_prev_safe(pos, n, head) \ for (pos = (head)->prev, n = pos->prev; \ pos != (head); \ pos = n, n = pos->prev)
遍历entry
我们直到container_of的作用是获取list的上层结构体,而遍历的作用是从头遍历list所有成员。
那么遍历entry的含义就是两者的结合版本,通过list_for_each遍历所有list,然后通过entry获取上层结构体,其代码如下
#define list_for_each_entry(pos, head, member) \ for (pos = list_first_entry(head, typeof(*pos), member); \ !list_entry_is_head(pos, head, member); \ pos = list_next_entry(pos, member))
可以看到这里的pos不再是list某个成员,而是所带list的上层结构体entry了。
安全遍历entry
遍历entry也有安全函数版本,如果在循环内部需要删除pos,那么请使用安全版本,其代码如下
#define list_for_each_entry_safe(pos, n, head, member) \ for (pos = list_first_entry(head, typeof(*pos), member), \ n = list_next_entry(pos, member); \ !list_entry_is_head(pos, head, member); \ pos = n, n = list_next_entry(n, member))
自己的实现
上面把内核的实现捋了一遍,我又翻箱倒柜找到了自己当时list.h的实现。这里也简单分析一下。
自己的list实现思路是参考了内核,但没内核写的高级,纯粹按照个人思路完成。本人多个工程都用此list.h文件,目前没什么问题。最后贴上list.h的个人版本所有代码
结构体
结构体和内核一致
struct list_head { struct list_head *prev; struct list_head *next; };
初始化
和内核一致,但是不考虑变量的原子性
static inline void list_inithead(struct list_head *item) { item->prev = item; item->next = item; }
list_add
添加的两个版本没有内核的抽象,我的思路如下 首先默认情况如下
list<---> A
此时添加item,首先先把item的prev和next接到list和A中间
list<---item--->A
item->prev = list; item->next = list->next;
此时A的prev是断开的,list的next也是断开的,修复doubly link list关系
list<--->item<--->A
list->next->prev = item; list->next = item;
故代码如下
static inline void list_add(struct list_head *item, struct list_head *list) { item->prev = list; item->next = list->next; list->next->prev = item; list->next = item; }
list_addtail
tail的版本是添加到list之前,假设默认情况如下
A<--->list
此时添加item,首先先把item的prev和next接到list和A中间
A<---item--->list
item->next = list; item->prev = list->prev;
此时A是list->prev,其next是断开的,list的prev也是断开的,修复一下
A<--->item<--->list
list->prev->next = item; list->prev = item;
故代码如下
static inline void list_addtail(struct list_head *item, struct list_head *list) { item->next = list; item->prev = list->prev; list->prev->next = item; list->prev = item; }
list_del
首先默认情况如下
list<--->item<--->B
我们幻想一个删除后的结果如下
list<---?--->B
所以在item角度修复其item->prev->next和item->next->prev
list<--->B
item->prev->next = item->next; item->next->prev = item->prev;
个人的实现没有内核的标记,所有直接置空即可,故整体代码如下
static inline void list_del(struct list_head *item) { item->prev->next = item->next; item->next->prev = item->prev; item->prev = item->next = NULL; }
list_validate
在解决《glibc的chunk破坏问题》问题的时候,我特地实现了validate函数,此函数判断doubly link list的每个成员是否正常,其思路是
- 判断每个成员的next的prev是不是自己
- 判断每个成员的prev的next是不是自己
static inline void list_validate(const struct list_head *list) { struct list_head *node; assert(list_is_linked(list)); assert(list->next->prev == list && list->prev->next == list); for (node = list->next; node != list; node = node->next) assert(node->next->prev == node && node->prev->next == node); }
list_splice
拼接的思路上文已经叙述清楚了,这里绘图示意即可。假设默认两个list如下
tail(A)<--->src<--->A dst<--->B
第一步,将src拆开,将A的prev挂到dst,将tail的next挂到B上。为了简化,假设tail就是A。
dst<---A(tail)--->B
src->next->prev = dst; src->prev->next = dst->next;
第二步,将B的prev设置为tail(A)
dst<---A(tail)<--->B
dst->next->prev = src->prev;
第三步,将dst的next设置为A
dst<--->A(tail)<--->B
dst->next = src->next;
此时拼接完成,故整体代码如下
static inline void list_splice(struct list_head *src, struct list_head *dst) { if (list_is_empty(src)) return; src->next->prev = dst; src->prev->next = dst->next; dst->next->prev = src->prev; dst->next = src->next; }
list_splicetail
拼接尾的思路完全一致,不同的是拼接到head前面。假设默认两个list如下
tail(A)<--->src<--->A tail(B)<--->dst<--->B
第一步,将src拆开,将tail(A)的next挂到dst,将A的prev挂到tail(B)上。
tail(B)<---tail(A)--->dst
src->prev->next = dst; src->next->prev = dst->prev;
第二步,将tail(B)的next设置为A
tail(B)<--->tail(A)--->dst
dst->prev->next = src->next;
第三步,将dst的prev设置为tail(A)
tail(B)<--->tail(A)--->dst
dst->prev = src->prev;
值得注意的是,如果此链表只要一个元素A/B,那么tail(A)就是A,tail(B)就是B,如果是多个元素,你也可以理解tail(A)是src的最后一个元素,tail(B)是dest的最后一个元素。
entry及其衍生
关于list_entry的宏定义,可以直接从内核抄,只不过我们需要替换成标准的offsetof实现,如下
#define list_entry(__item, __type, __field) \ ((__type *)(((char *)(__item)) - offsetof(__type, __field)))
在此之上list_for_each和list_for_each_entry的实现可以无缝复制粘贴
当然,其safe实现也可以无缝粘贴。
代码
#ifndef _LIST_H_ #define _LIST_H_ #include <stdbool.h> #include <stddef.h> #include <assert.h> #define list_assert(cond, msg) assert(cond && msg) struct list_head { struct list_head *prev; struct list_head *next; }; static inline void list_inithead(struct list_head *item) { item->prev = item; item->next = item; } static inline void list_add(struct list_head *item, struct list_head *list) { item->prev = list; item->next = list->next; list->next->prev = item; list->next = item; } static inline void list_addtail(struct list_head *item, struct list_head *list) { item->next = list; item->prev = list->prev; list->prev->next = item; list->prev = item; } static inline bool list_is_empty(const struct list_head *list) { return list->next == list; } static inline void list_replace(struct list_head *from, struct list_head *to) { if (list_is_empty(from)) { list_inithead(to); } else { to->prev = from->prev; to->next = from->next; from->next->prev = to; from->prev->next = to; } } static inline void list_del(struct list_head *item) { item->prev->next = item->next; item->next->prev = item->prev; item->prev = item->next = NULL; } static inline void list_delinit(struct list_head *item) { item->prev->next = item->next; item->next->prev = item->prev; item->next = item; item->prev = item; } static inline bool list_is_linked(const struct list_head *list) { assert((list->prev != NULL) == (list->next != NULL)); return list->next != NULL; } static inline bool list_is_singular(const struct list_head *list) { return list_is_linked(list) && !list_is_empty(list) && list->next->next == list; } static inline unsigned list_length(const struct list_head *list) { struct list_head *node; unsigned length = 0; for (node = list->next; node != list; node = node->next) length++; return length; } static inline void list_splice(struct list_head *src, struct list_head *dst) { if (list_is_empty(src)) return; src->next->prev = dst; src->prev->next = dst->next; dst->next->prev = src->prev; dst->next = src->next; } static inline void list_splicetail(struct list_head *src, struct list_head *dst) { if (list_is_empty(src)) return; src->prev->next = dst; src->next->prev = dst->prev; dst->prev->next = src->next; dst->prev = src->prev; } static inline void list_validate(const struct list_head *list) { struct list_head *node; assert(list_is_linked(list)); assert(list->next->prev == list && list->prev->next == list); for (node = list->next; node != list; node = node->next) assert(node->next->prev == node && node->prev->next == node); } static inline void list_move_to(struct list_head *item, struct list_head *loc) { list_del(item); list_add(item, loc); } #define list_entry(__item, __type, __field) \ ((__type *)(((char *)(__item)) - offsetof(__type, __field))) #define list_container_of(ptr, sample, member) \ (void *)((char *)(ptr) \ - ((char *)&(sample)->member - (char *)(sample))) #define list_first_entry(ptr, type, member) \ list_entry((ptr)->next, type, member) #define list_last_entry(ptr, type, member) \ list_entry((ptr)->prev, type, member) #define LIST_FOR_EACH_ENTRY(pos, head, member) \ for (pos = NULL, pos = list_container_of((head)->next, pos, member); \ &pos->member != (head); \ pos = list_container_of(pos->member.next, pos, member)) #define LIST_FOR_EACH_ENTRY_SAFE(pos, storage, head, member) \ for (pos = NULL, pos = list_container_of((head)->next, pos, member), \ storage = list_container_of(pos->member.next, pos, member); \ &pos->member != (head); \ pos = storage, storage = list_container_of(storage->member.next, storage, member)) #define LIST_FOR_EACH_ENTRY_SAFE_REV(pos, storage, head, member) \ for (pos = NULL, pos = list_container_of((head)->prev, pos, member), \ storage = list_container_of(pos->member.prev, pos, member); \ &pos->member != (head); \ pos = storage, storage = list_container_of(storage->member.prev, storage, member)) #define LIST_FOR_EACH_ENTRY_FROM(pos, start, head, member) \ for (pos = NULL, pos = list_container_of((start), pos, member); \ &pos->member != (head); \ pos = list_container_of(pos->member.next, pos, member)) #define LIST_FOR_EACH_ENTRY_FROM_REV(pos, start, head, member) \ for (pos = NULL, pos = list_container_of((start), pos, member); \ &pos->member != (head); \ pos = list_container_of(pos->member.prev, pos, member)) #define list_for_each_entry(type, pos, head, member) \ for (type *pos = list_entry((head)->next, type, member), \ *__next = list_entry(pos->member.next, type, member); \ &pos->member != (head); \ pos = list_entry(pos->member.next, type, member), \ list_assert(pos == __next, "use _safe iterator"), \ __next = list_entry(__next->member.next, type, member)) #define list_for_each_entry_safe(type, pos, head, member) \ for (type *pos = list_entry((head)->next, type, member), \ *__next = list_entry(pos->member.next, type, member); \ &pos->member != (head); \ pos = __next, \ __next = list_entry(__next->member.next, type, member)) #define list_for_each_entry_rev(type, pos, head, member) \ for (type *pos = list_entry((head)->prev, type, member), \ *__prev = list_entry(pos->member.prev, type, member); \ &pos->member != (head); \ pos = list_entry(pos->member.prev, type, member), \ list_assert(pos == __prev, "use _safe iterator"), \ __prev = list_entry(__prev->member.prev, type, member)) #define list_for_each_entry_safe_rev(type, pos, head, member) \ for (type *pos = list_entry((head)->prev, type, member), \ *__prev = list_entry(pos->member.prev, type, member); \ &pos->member != (head); \ pos = __prev, \ __prev = list_entry(__prev->member.prev, type, member)) #define list_for_each_entry_from(type, pos, start, head, member) \ for (type *pos = list_entry((start), type, member); \ &pos->member != (head); \ pos = list_entry(pos->member.next, type, member)) #define list_for_each_entry_from_safe(type, pos, start, head, member) \ for (type *pos = list_entry((start), type, member), \ *__next = list_entry(pos->member.next, type, member); \ &pos->member != (head); \ pos = __next, \ __next = list_entry(__next->member.next, type, member)) #define list_for_each_entry_from_rev(type, pos, start, head, member) \ for (type *pos = list_entry((start), type, member); \ &pos->member != (head); \ pos = list_entry(pos->member.prev, type, member)) #endif
上述代码和内核一样,声明成list.h就可搬到代码使用了。
总结
本文重新分析了内核list的实现,并找到了原来自己写的list.h。可以发现,对于不同的list实现,思路并不是一样的。
我在分析内核的实现的时候,还得停下来想一会儿,才能清楚。但是分析自己原来写的东西的时候,一下就知道当时自己为什么这么写,很快就给出了图示。
所以人的思维还是有一定定式的,如果是内核的实现方式方式,我并不一定能想到并写出来。而自己的实现又没有常常去复习。所以这才是我现场写不出来一个双向循环链表的根本原因吧,自省之~
我们自己使用的服务器,经常需要编译代码等操作,并且是多人并行使用的服务器状态,使用久了的情况下,服务器经常会出现如下问题。
- OOM
- 卡死
- 短时间无响应
- 无法申请内存
- 编译代码缓慢
对于我这么多年使用服务器的经验而言,其实一直都是在平衡上面五个问题的状态,让其在上面五个问题中间得到平衡,而不因为某个点导致服务器的性能下降。
可见对于不同场景的服务器,需要为其设置不同的内存调节状态,本文基于编译型服务器,提出关于内存调节的一下想法和见解。这会对使用服务器有更好的理解。
只有拥有一个调教好的服务器,才能发挥利用服务器发挥自己最大的工作效率
默认的swap配置
linux默认配置swappiness是60,通常情况下,这个值的范围是0-100,值越高,则回收的时候优先选择匿名页,然后将匿名页搬运到swap分区中,值越低,会减少swap的使用,从而由其他参数调节page cache的行为
为什么首先谈这个呢。根据上面理解的,swappiness默认是60,那么从某种平衡上来看,如果系统存在内存压力的情况下,会稍微将anon page移到swap 分区中。那么将anon page移到swap 分区因为IO带来的性能损失和延迟对绝大部分人是能够接收的,这样就不至于可能出现系统完全无内存导致的oom情况。
根据默认值60,我们知道,linux内核考虑了很通用的情况下,牺牲一些性能从而满足内存在压力情况下的可用。
而面对服务器而言,特别是编译型服务器,我们每个编译任务可能是长时间,但一定会完成的,所以不希望移到swap分区,如果维持在60的值,大型任务例如llvm,chromium的构建就会很慢。所以需要降低swappiness的值
那我们设置swappiness的值是0还是1呢。根据长时间的经验来看,总结如下
- 当不开swap分区的情况下:更容易出现OOM
- 设置为0:当内存不足时,仍可能出现oom,只在内存非常低的情况下使用swap,且使用很少
- 设置为1:当内存不足时,还是会将部分anon page移动到swap,如果系统内存不足,不会立即oom,而是尽可能使用swap
可以看到,根据使用经验而言,swappiness在编译型服务器上,应该很低,但是如果设置为0,那么swap分区即使设置了很大,内核还是不会使用swap分区的空间,而是直接oom。那么推荐swappiness的值是1。当内存不够的时候,才将swap分区利用起来
根据swappiness的配置,我们能够解决默认情况下编译代码缓慢的问题,因为系统不再将anon page移动到swap 分区中了,也不会突然因为不当的swappiness设置导致oom情况出现,编译速度得到了加快。
drop_caches
根据上面的设置,系统默认不使用swap分区了,那么所有的任务都更倾向于使用内存了,对于很多人而言,都了解一个配置 drop_caches ,认为drop_caches能够通过定期任务减缓内存压力。
按照本人理解,其实 drop_caches 是清空page cache和slab cache
如果我们echo 1 > /proc/sys/vm/drop_caches那么情况的是page cache。 具体而言是清空处于inactive链表的page cache,实验如下:
未清空page cache如下
root@kylin:~# cat /proc/meminfo | grep -i active Active: 1361888 kB Inactive: 46626572 kB Active(anon): 843576 kB Inactive(anon): 387512 kB Active(file): 518312 kB Inactive(file): 46239060 kB
此时我们运行# echo 1 > /proc/sys/vm/drop_caches得到信息如下
root@kylin:~# cat /proc/meminfo | grep -i active Active: 1023844 kB Inactive: 438784 kB Active(anon): 862328 kB Inactive(anon): 368504 kB Active(file): 161516 kB Inactive(file): 170280 kB
可以看到,处于inactive上的46G内存得到了释放
接下来看drop_caches对slab的清空情况。首先我们知道slab的值是SReclaimable+SUnreclaim。而同样的drop_caches针对的是可回收的内存,也就是SReclaimable,而不是不可回收的内存SUnreclaim,演示如下
root@kylin:~# cat /proc/meminfo | grep -i slab -A 2 Slab: 3724284 kB SReclaimable: 3116412 kB SUnreclaim: 607872 kB root@kylin:~# echo 2 > /proc/sys/vm/drop_caches root@kylin:~# cat /proc/meminfo | grep -i slab -A 2 Slab: 602276 kB SReclaimable: 115296 kB SUnreclaim: 486980 kB
可以看到,对于SReclaimable对于的内存,得到了回收。
实际上,对于编译型服务器,这里更多是dentry cache,也就是文件系统访问缓存,我们演示一下如下
# cat /proc/sys/fs/dentry-state 97122 77478 45 0 53596 0 # echo 2 > /proc/sys/vm/drop_caches && cat /proc/sys/fs/dentry-state 17018 23 45 0 1065 0
可以看到,nr_unused从7万变为23了,内存从这里得到了释放
针对此,很多人,包括早期我自己也很喜欢定期执行 sync和drop_cachessync && echo 1 > /proc/sys/vm/drop_caches。 sync的目的是将脏页写回,这样可回收的内存就会变多。但是根据上面的了解,其缺点也很明显,针对编译型服务器,其dentry cache得到了错误的清除,导致编译速度变慢了,不仅如此,服务器还会出现概率卡死。
但实际上,如果我们了解内存的配置,其实无需定期执行,而是由kernel的self tuning。会比定期执行更好。
self tuning
根据上面提到的drop_caches,我们先讨论page caches的回收,这里借助lorenzo stoakes编写《the linux memory manager》一张图如下
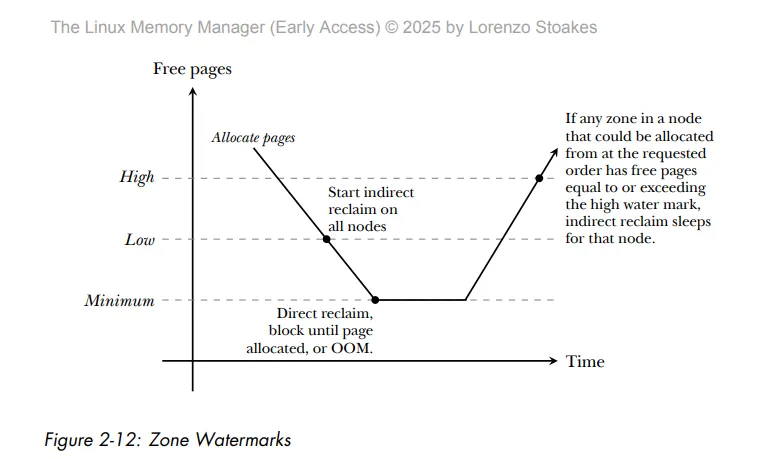
根据此图,可以看到很熟悉的一个机制,那就是linux 水位机制,这里简单回顾一下
- 当可用内存在水位low时,kswapd唤醒,开始非直接回收
- 当可用内存在水位min时,开启阻塞性的直接回收
- 如果此时内存剩余内存太小,或内存回收失败,则从进程列表中找到得分最低的进程oom杀掉。保障直接回收成功
- 当可用内存在水位high时,kswapd休眠
可以知道,如果内存压力太大,那么内核会自己回收内存,而不需要自己定期的drop_caches
其二,对于slab cache的self tuning方式,如下
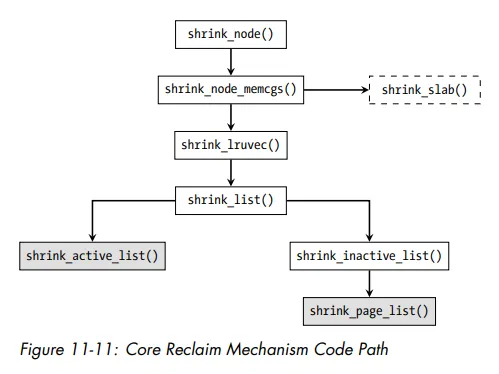
这里可以看到,slab默认的shrink机制能够自动回收slab cache。其机制也属于关于slab的indirect/direct reclaim回收,所以也符合水位机制。
调整self tuning
根据上面介绍的,我们可以针对性的调整水位的比例。
针对编译型服务器,根据多年的使用经验,那么可能出现如下问题
- 内存突然不足,直接可用内存到min以下,导致cc程序直接oom
- 内存申请和回收的生产者消费者不成比例,导致从low到min的速度很快,从而机器无响应
可以看到,默认的配置还是不满足编译型服务器,我们需要针对性的修改sysctl,如下
解决内存不足直接oom
对于min一下无可用内存,直接oom的情况,我们可以修改min_free_kbytes的值,通常min_free_kbytes的值也是内核通过当前所有zones的总和计算出来的,为了考虑常规情况,此值通常偏低了点,为了应对编译型服务器,那么需要设置高点,多高呢。我们可以对照内核的init_per_zone_wmark_min函数查看
int __meminit init_per_zone_wmark_min(void) { ...... min_free_kbytes = new_min_free_kbytes; if (min_free_kbytes < 128) min_free_kbytes = 128; if (min_free_kbytes > 262144) min_free_kbytes = 262144; ...... return 0; }
可以知道,内核最大可以设置到256M,鉴于我们是服务器,内存本身就很大,所以我们可以设置为256,如下
echo 262144 > /proc/sys/vm/min_free_kbytes
不过这个是根据实际情况,太大了也不一定好,个人建议设置到0.05%。也就是对于128G内存,设置到64M。
设置完了之后,可以长期监听vmstat的kswapd_low_wmark_hit_quickly 来判断你的服务器设置的值是否合理,如下
# cat /proc/vmstat | grep kswapd_low_wmark_hit_quickly kswapd_low_wmark_hit_quickly 358635
这个值代表kswapd到low水位的次数,这里我已经到358635次了。这里值得注意的是,这个次数不是越高越好,也不是越低越好。是根据情况查看增长速率,如下:
- 如果服务器任务较少,此值不应该快速上涨。否则服务器的内存设置有问题
- 如果服务器任务较多,此值不应该缓慢增长。否则服务器回收内存效率太低
这样,我们当内存不够的时候,我们就不会出现无法direct reclaim导致的oom情况了。
解决机器无响应
如果内存从low到min速度太快,又因为直接回收是阻塞的,所以我们经常发现服务器突然卡死了。 通常这种情况下,如果没有什么重要的事情,那么等一会儿就好了。
直接解决此问题的方式就是增加内存,例如32G的内存可以增加到128G,128G的内存可以增加到256G。
这里讨论的是既不想等一会儿自己恢复,又短时间无法增加服务器内存的情况。
针对这种情况,解决方案也很容易想到,我们扩大low到min的距离,也就是,假设min是64M,那我low是640M行不行呢?
很可惜的是,内核只提供了比例设置,不提供具体的值的设置。我们可以设置watermark_scale_factor来缓解这个问题
watermark_scale_factor控制了kswapd的主动性,默认其分母是10000,其值设置是10,那么是0.1%比率作为计算,也就是high与low的差距是总内存的0.1%。
针对此问题,缓解的方法是设置watermark_scale_factor大一点,具体多大呢,需要根据如下值的增长情况判断,
root@kylin:# cat /proc/vmstat |grep 'allocstall' allocstall_dma32 0 allocstall_normal 173606 allocstall_movable 4338981
这里arm64没有ZONE_DMA,不用奇怪,我们监控normal和movable的allocstall值,如果这个值变大,那么需要将watermark_scale_factor放大。
echo 40 > /proc/sys/vm/watermark_scale_factor
根据经验,调整watermark_scale_factor并不能改善无响应的问题,因为内存不够就是不够,只是改善进入直接回收的时机,也就是扩大水位线之间的差距,从而减少系统无响应的次数
overcommit
默认情况下,内核设置了overcommit_memory的值是0,意味着如果没有可用内存,则申请内存失败。它会影响到一些大型任务构建是否成功。
也就是说,有时候会因为内存不够,导致某些程序无法编译成功,所以有些情况下,我们需要设置overcommit_memory为1如下
echo 1 > /proc/sys/vm/overcommit_memory
这里含义如下
- OVERCOMMIT_GUESS:适度过度提交,当大块内存申请时会拒绝
- OVERCOMMIT_ALWAYS: 允许分配,后果自己负责
- ERCOMMIT_NEVER:不overcommit
值得注意的是,如果设置为1,那么可能会导致oom,理由可想而知。
脏页回收
上面已经说明清楚了内核关于内存的回收流程,但服务器的配置光内存的回收还不够,我们需要控制脏页的回收策略。
对于脏页的回收设置,有一个文章推荐设置具体的值,而不是比率。如下
所以我们设置脏页回收策略根据值来配置。
vm.dirty_ratio = 0 vm.dirty_bytes = 629145600 # keep the vm.dirty_background_bytes to approximately 50% of this setting vm.dirty_background_bytes = 314572800
值得注意的是默认情况下,设置的dirty_bytes是0,而dirty_ratio是20。所以对于编译型服务器而言,这里必须修改一下。
dentry的回收
上面可以看到slab的SReclaimable回收来源于dentry,因为我们是编译型服务器,所以我们需要调整vfs_cache_pressure。
vfs_cache_pressure的作用是回收文件系统缓存,如果我们内存吃紧,还容易出现OOM,那么就增高此值,如果内存足够,则降低此值。
为了让服务器能够编译,并且保留缓存,我更倾向于降低此值。
echo 50 > /proc/sys/vm/vfs_cache_pressure
如果你编译大型任务,发现出现OOM了,那么就增大此值
echo 500 > /proc/sys/vm/vfs_cache_pressure
总结
至此,我总结了这些年和服务器斗智斗勇的这些配置,在不同情况下,需要设置的不一样。 对于从事操作系统开发而言,成千上万的软件包要构建和开发,那么服务器就是纯编译型服务器,那么这种情况下针对内存情况的配置如下。
如果内存吃紧,那么如下配置
echo 1 > /proc/sys/vm/swappiness echo 262144 > /proc/sys/vm/min_free_kbytes echo 40 > /proc/sys/vm/watermark_scale_factor echo 1 > /proc/sys/vm/overcommit_memory echo 629145600 > /proc/sys/vm/dirty_bytes echo 314572800 > /proc/sys/vm/dirty_background_bytes echo 500 > /proc/sys/vm/vfs_cache_pressure
值得注意的是
- 256M内存作为min,取决于总内存大小
- 40的watermark_scale_factor只能改善无响应情况
- overcommit_memory设置为1可能导致OOM(取决于回收情况),但不会让任务编译失败
- 600M的dirty_bytes,取决于总内存大小
- vfs_cache_pressure用于积极回收slab caches
这样设置的情况下,编译任何工程都能工作
如果服务器内存本来就多,这个问题就变得简单了
1. 无需swap分区 2. 增大dirty_bytes 3. vfs_cache_pressure设置为1
当然,那不现实,写到这里,不禁发出感叹:
- 内存就像生活,富人无需思考琐碎,穷人才会步履维艰。
对于开头提到的问题解决效果呢,如下
- OOM : 改善
- 卡死: 解决
- 短时间无响应:改善
- 无法申请内存 :解决
- 编译代码缓慢 :解决
