目录
LRU算法全称是Least recently used,最近最少使用算法,他作为Linux内核页面置换算法的默认选择。原理是通过设置一个容量,LRU会选择最近最少使用的数据,并将其删除,这样能够保证了一定的容量的角度上提高系统的最大性能。
最近突然产生了一个思考,LRU算法作为缓存系统常用算法,在用户空间是否有人实现过了呢。结果发现,LRU算法可以看到在python,go,java等高级语言上实现,而在C上的单独实现全网几乎没有。
鉴于此,本文从介绍LRU算法开始,然后自己通过C语言实现了LRU算法,并进行了详细的测试,并整理文档,如有需要设计缓存系统,此代码开箱即用。
常见页面替换算法
在Linux中,所有的页面申请通过缺页异常产生,当系统没有足够空闲的页帧提供时,就需要腾挪一下页出来。那么腾挪的办法有如下几种
- OPT
- FIFO
- LRU
接下来简单介绍这些常见的替换算法
OPT
OPT也就是Optimal Page Replacement,最佳页面替换算法,其思路是永远先替换内存中最不经常使用的页面,但是如何从代码角度获得内存中最不经常使用的页面呢?
实际上,这是不现实的,因为代码层面无法准确的预计到以后哪些页面会被访问,所以无法知道哪些页面是最不经常使用的。 但是在非代码层面,例如我们在做理论分析的时候,此算法可以用于分析和衡量其他算法的实际效率。
FIFO
FIFO也就是First In First Out ,先入线程页面替换算法,其思路很简单,就是利用FIFO的特性,让所有先进入队列的页面先删除,其优点是代码设计非常简单,例如使用循环链表就能轻松实现,但是缺点是其实际应用效率并不高。
因为在实际场景中,先加入的页面,可能会被多次访问,如果使用FIFO置换页面,那么如果访问先加入的页面,那么就会频繁的换入换成,很容易造成系统颠簸。
所以在讨论页面置换的场景下,不能单纯的忽略历史数据的再次访问的情况。所以FIFO不是更好的置换算法
LRU
LRU也就是Least Recently Used,最近最少使用页面替换算法,根据刚刚讨论FIFO的缺陷,我们不能单纯的忽略历史数据,所以LRU算法应运而生
如果我们将最近访问的历史数据的优先级进行排序,那么我们就从FIFO算法转变成LRU算法,那样,每次页面替换时,默认将未被访问的先进入缓存队列的页面换出,任何被重复访问的数据都保存到优先级最高的队列头。
LRU的实现
根据上面几种算法的讨论,我们清晰的了解了LRU算法的基本原理,现在可以思考其实现思路。
- 首先,我们肯定需要通过一个循环单链表来实现FIFO的策略
- 其次,我们需要将链表尾数据挪动到链表头,所以基于循环单链表的FIFO需要修改成循环双链表,其时间复杂度是O(1)
- 再者,每次访问缓存中的页面元素时,如果从双链表中寻找,那么遍历链表复杂度是O(n),为了提高性能,可以使用hash,使其变成O(1)
- 最后,因为hash的碰撞问题,我们可以选择开发寻址法或链表法,鉴于链表法更简单,所以我使用链表法
这样基于 hash 和 doubly link list 的实现能够以最高的效率实现LRU算法,其理论是O(1),但实际是O(1)-O(n)中间,为什么呢?
因为hash存在碰撞,其碰撞情况取决于负载因子(load facotr),其计算如下load factor = capacity / slots,如果slots越大,那么hash碰撞更低,则寻找缓存页面元素的时间复杂度是O(1),如果slots为1,那么hash碰撞情况为100%,每次寻找缓存页面元素都需要遍历链表,则其时间复杂度是O(n),那么合适的设计load factor就是LRU算法的性能关键。
最终实现的LRU算法应该提供如下两个函数
- lru_get(key)
- lru_put(key,value)
get的实现
因为hash的特性,我们需要设计键值对,我们不需要完全实现一个完整意义上的hash去实现LRU,我们只需要保证key相同时,hash找到缓存value的效率是O(1)即可。 举个例子:
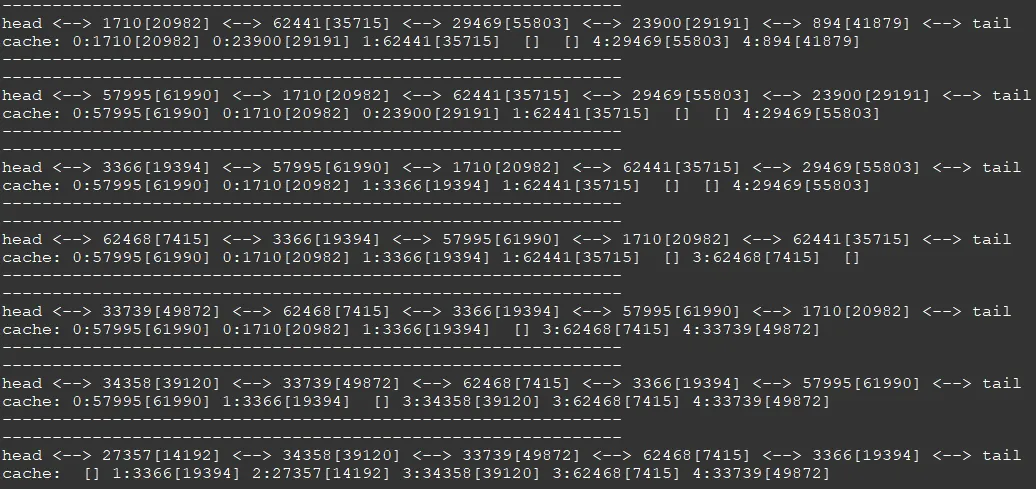
如果slots=10,此时key是22,那么lru_get将获取 22 % 10 ,也就是 slot=2 中的元素。又因为slot = 2 中存放的是链表,那么遍历此链表中的元素,找到key == 22 的value即可返回。
可以发现,如果slot=2 的链表有多个元素,那么证明hash还是存在碰撞,此时不是完全的O(1),但是如果slot=2只有key == 22 一个元素,那么遍历链表就是寻找其下一个节点而已,那么就是完全意义上的O(1)
如果lru_get时,key 不再任何一个槽中,则返回-1,代表lru中没有此缓存值
put的实现
关于put的实现,我们需要留意如下几个步骤
- 如果通过hash寻找到缓存,则更新value,其方法与get一致,但多了一步,就是将匹配到的节点移动到双链表头部
- 如果找不到缓存,则新建一个节点
- 因为新建了一个节点,所以需要判断链表的大小是否大于缓存的容量,如果大于,则从双链表尾部踢出一个节点
这样也就实现了LRU算法的本意,最近最少使用,最近的意思是在容量中的缓存,最少的意思是在容量中最后一个节点。组合起来就是:当新增节点时,将容量中最不经常使用的,也就是最后一个节点踢出
值得注意的是,这里虽然提到了最后一个节点是最不经常使用的,但实际上是无需使用任何排序算法的,其原因是链表的隐藏特性,对于链表的添加,都是从链表的头/尾添加,这样就已经隐式的在链表中排序了,链表最后一个节点就是最早进入链表的节点。
总结
上文比较详细的介绍了LRU算法的理论知识,可以让未对LRU算法了解的人有一个清晰的认知,本人的本意是发现Linux发行平台上,使用LRU算法的C实现例子偏少(内核外),所以抽空周末实现了C语言的LRU版本,为了介绍此版本LRU算法的目的而产生。
在实现过程中也踩了一点坑,那就是按照自己的想法,没有实现hash去解决查询的效率问题,而是通过遍历的方式寻找的key,但是后面通过网页检索回顾才发现,可以实现一个hash,将O(n)降低为0(1)。后面我又翻阅了不同开源仓库的LRU实现方法,基于开放寻找法和链表法都做了实现,但发现链表法更直接有效,所以又根据自己理解进行了完善LRU的实现。
下面是一个测试的例子