目录
LRU的代码实现比较清晰,一个是双链表,一个是hash,这里以自己实现的LRU算法为例进行代码解析
数据结构
链表
链表的实现在《C语言双向链表的个人实现版》中,直接可以获取
hash
hash的实现是通过链表实现的,也就是拉链的方式。如下图所示
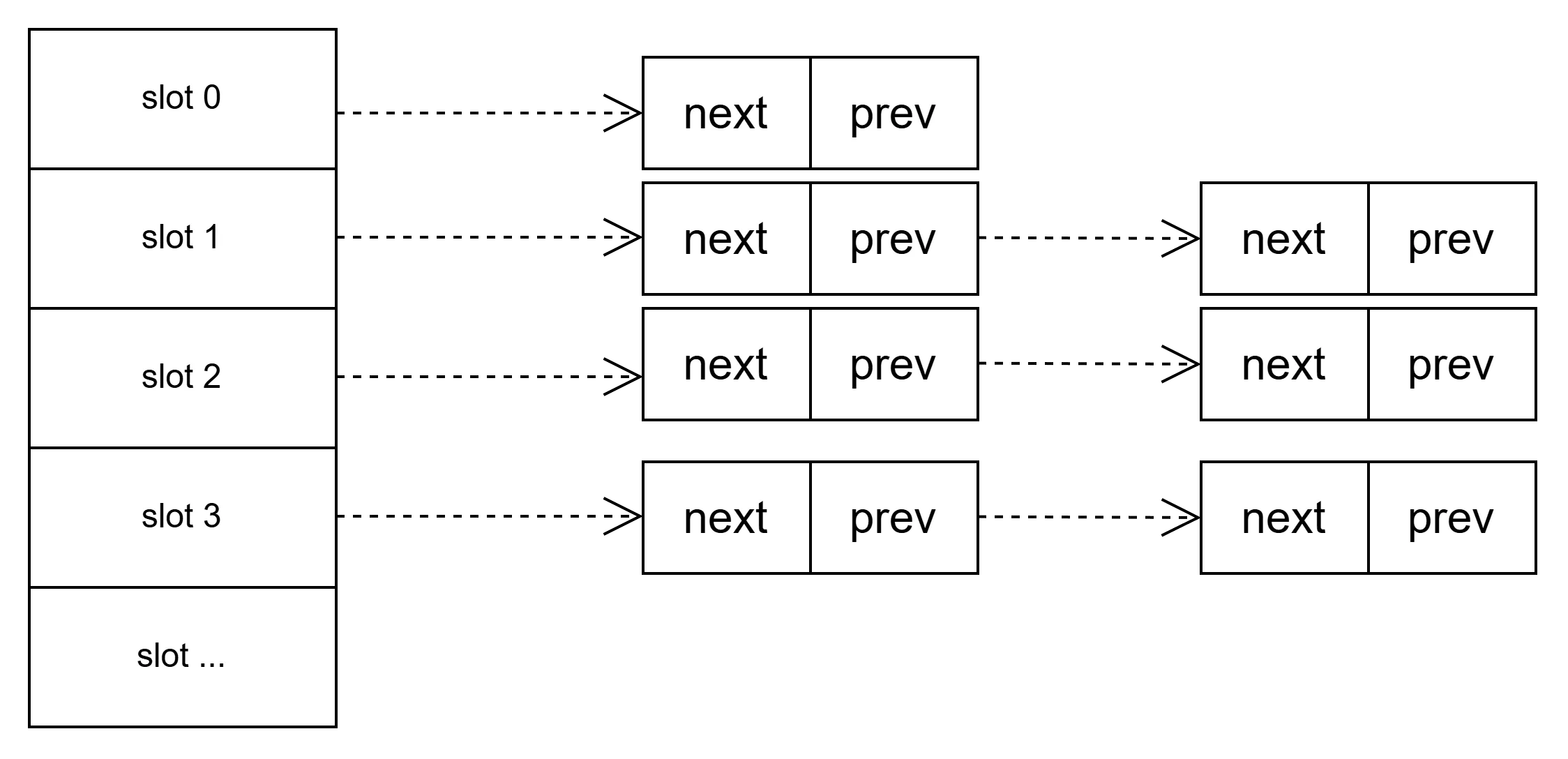
结构
所以根据上面的组合,其代码数据结构如下
typedef struct { int key; int value; struct list_head hash_list; struct list_head lru_list; } lru_node_t; typedef struct { int size; int capacity; int nr_slot; struct list_head *slots; struct list_head lru_head; } lru_cache_t;
- key/value用作LRU元素键值对
- hash_list是拉链的链条,用作每个slot的双链表
- lru_list是维护LRU的双链表
- size记录当前LRU缓存容量
- capacity为LRU最大缓存容量
- slots是拉链结构,里面存放hash_list链条
- lru_head作为LRU的双链表头
此数据比较清晰,这样通过两个链表就组合成了LRU算法的结构体
lru_get的实现
get的实现比较容易,就是从拉链中寻找节点,如果节点不是空,则遍历链表。
- 如果链表长度就是1,也就是没有碰撞,那么其时间复杂度就是O(1)
- 如果链表长度大于1,那么其复杂度就是遍历此链表的复杂度
代码如下:
int lru_get(lru_cache_t* cache, int key) { int index = key % cache->nr_slot; if(cache == NULL) return -1; if(list_is_empty(&cache->slots[index])) return -1; list_for_each_entry_safe(lru_node_t, pos, &cache->slots[index], hash_list) { if(key == pos->key) { list_move_to(&pos->lru_list, &cache->lru_head); return pos->value; } } return -1; }
lru_put的实现
put的实现稍微麻烦点,需要先判断节点是否存在,然后再新建节点和踢出旧节点
- 如果拉链存在节点,则遍历拉链的链表,同get方法,然后将找到的节点移动到lru_list的头部
- 如果拉链不存在节点,则新建节点,加入对于的slot链表和lru链表
- 如果当前lru的节点数量大于容量,则删除lru链表的尾部节点
void lru_put(lru_cache_t* cache, int key, int value) { lru_node_t* node; int index = key % cache->nr_slot; if(cache == NULL) return; if(!list_is_empty(&cache->slots[index])) { list_for_each_entry(lru_node_t, pos, &cache->slots[index], hash_list) { if(key == pos->key) { pos->value = value; list_move_to(&pos->lru_list, &cache->lru_head); return; } } } node = malloc(sizeof(lru_node_t)); node->value = value; node->key = key; list_inithead(&node->hash_list); list_inithead(&node->lru_list); cache->size++; list_add(&node->lru_list, &cache->lru_head); list_add(&node->hash_list, &cache->slots[index]); if (cache->size > cache->capacity) { lru_removetail(cache, node); } return; }
测试
为了测试LRU,这里以四篇文章,这里标题以文章标题为例,文章链接后面参考文献提供,测试数据以其提供数据示例做验证。如下
ref: "Design LRU Cache"
这里给出信息如下
Input: [LRUCache cache = new LRUCache(2) , put(1 ,1) , put(2 ,2) , get(1) , put(3 ,3) , get(2) , put(4 ,4) , get(1) , get(3) , get(4)] Output: [1 ,-1, -1, 3, 4]
实际测试结果如下
# ./lru -------------------------------------------------------------- head <--> 1[1] <--> tail cache: [] 1:1[1] -------------------------------------------------------------- -------------------------------------------------------------- head <--> 2[2] <--> 1[1] <--> tail cache: 0:2[2] 1:1[1] -------------------------------------------------------------- lru_get key=1 value=1 -------------------------------------------------------------- head <--> 1[1] <--> 2[2] <--> tail cache: 0:2[2] 1:1[1] -------------------------------------------------------------- -------------------------------------------------------------- head <--> 3[3] <--> 1[1] <--> tail cache: [] 1:3[3] 1:1[1] -------------------------------------------------------------- lru_get key=2 value=-1 -------------------------------------------------------------- head <--> 3[3] <--> 1[1] <--> tail cache: [] 1:3[3] 1:1[1] -------------------------------------------------------------- -------------------------------------------------------------- head <--> 4[4] <--> 3[3] <--> tail cache: 0:4[4] 1:3[3] -------------------------------------------------------------- lru_get key=1 value=-1 -------------------------------------------------------------- head <--> 4[4] <--> 3[3] <--> tail cache: 0:4[4] 1:3[3] -------------------------------------------------------------- lru_get key=3 value=3 -------------------------------------------------------------- head <--> 3[3] <--> 4[4] <--> tail cache: 0:4[4] 1:3[3] -------------------------------------------------------------- lru_get key=4 value=4 -------------------------------------------------------------- head <--> 4[4] <--> 3[3] <--> tail cache: 0:4[4] 1:3[3] --------------------------------------------------------------
可以看到,在put 1,2时容量未满,正常put,当get 1时,会将1的优先级提高,在put 3的时候,会将2踢出,在get 2是,节点不存在返回-1
ref: "Page Replacement Algorithms in Operating Systems"
LRU中提供了测试数据如下
7, 0, 1, 2, 0, 3, 0, 4, 2, 3, 0, 3, 2, 3 with 4-page frames
其结果应该如下

实际测试结果如下
-------------------------------------------------------------- head <--> 7[7] <--> tail cache: [] [] [] 3:7[7] -------------------------------------------------------------- -------------------------------------------------------------- head <--> 0[0] <--> 7[7] <--> tail cache: 0:0[0] [] [] 3:7[7] -------------------------------------------------------------- -------------------------------------------------------------- head <--> 1[1] <--> 0[0] <--> 7[7] <--> tail cache: 0:0[0] 1:1[1] [] 3:7[7] -------------------------------------------------------------- -------------------------------------------------------------- head <--> 2[2] <--> 1[1] <--> 0[0] <--> 7[7] <--> tail cache: 0:0[0] 1:1[1] 2:2[2] 3:7[7] -------------------------------------------------------------- -------------------------------------------------------------- head <--> 0[0] <--> 2[2] <--> 1[1] <--> 7[7] <--> tail cache: 0:0[0] 1:1[1] 2:2[2] 3:7[7] -------------------------------------------------------------- -------------------------------------------------------------- head <--> 3[3] <--> 0[0] <--> 2[2] <--> 1[1] <--> tail cache: 0:0[0] 1:1[1] 2:2[2] 3:3[3] -------------------------------------------------------------- -------------------------------------------------------------- head <--> 0[0] <--> 3[3] <--> 2[2] <--> 1[1] <--> tail cache: 0:0[0] 1:1[1] 2:2[2] 3:3[3] -------------------------------------------------------------- -------------------------------------------------------------- head <--> 4[4] <--> 0[0] <--> 3[3] <--> 2[2] <--> tail cache: 0:4[4] 0:0[0] [] 2:2[2] 3:3[3] -------------------------------------------------------------- -------------------------------------------------------------- head <--> 2[2] <--> 4[4] <--> 0[0] <--> 3[3] <--> tail cache: 0:4[4] 0:0[0] [] 2:2[2] 3:3[3] -------------------------------------------------------------- -------------------------------------------------------------- head <--> 3[3] <--> 2[2] <--> 4[4] <--> 0[0] <--> tail cache: 0:4[4] 0:0[0] [] 2:2[2] 3:3[3] -------------------------------------------------------------- -------------------------------------------------------------- head <--> 0[0] <--> 3[3] <--> 2[2] <--> 4[4] <--> tail cache: 0:4[4] 0:0[0] [] 2:2[2] 3:3[3] -------------------------------------------------------------- -------------------------------------------------------------- head <--> 3[3] <--> 0[0] <--> 2[2] <--> 4[4] <--> tail cache: 0:4[4] 0:0[0] [] 2:2[2] 3:3[3] -------------------------------------------------------------- -------------------------------------------------------------- head <--> 2[2] <--> 3[3] <--> 0[0] <--> 4[4] <--> tail cache: 0:4[4] 0:0[0] [] 2:2[2] 3:3[3] -------------------------------------------------------------- -------------------------------------------------------------- head <--> 3[3] <--> 2[2] <--> 0[0] <--> 4[4] <--> tail cache: 0:4[4] 0:0[0] [] 2:2[2] 3:3[3] --------------------------------------------------------------
可以看到,前4个元素7,0,1,2正常put,接下来put 0 正常hit,调整0优先级最高,然后put 3 miss,插入节点3,踢掉节点7,然后再次 hit 节点0,插入节点4,最后节点2,3,0,3,2,3 都得到hit,每次都正常提高为最高优先级
ref: "LRU Page Replacement Algorithm"
这里提供数据如下
Consider a reference string 1, 2, 1, 0, 3, 0, 4, 2, 4. Let us say there are 3 empty memory locations (or slots) available.
理论会得到3-page hits和6-page faults。
实际测试结果如下
-------------------------------------------------------------- head <--> 1[1] <--> tail cache: [] 1:1[1] [] -------------------------------------------------------------- -------------------------------------------------------------- head <--> 2[2] <--> 1[1] <--> tail cache: [] 1:1[1] 2:2[2] -------------------------------------------------------------- -------------------------------------------------------------- head <--> 1[1] <--> 2[2] <--> tail cache: [] 1:1[1] 2:2[2] -------------------------------------------------------------- -------------------------------------------------------------- head <--> 0[0] <--> 1[1] <--> 2[2] <--> tail cache: 0:0[0] 1:1[1] 2:2[2] -------------------------------------------------------------- -------------------------------------------------------------- head <--> 3[3] <--> 0[0] <--> 1[1] <--> tail cache: 0:3[3] 0:0[0] 1:1[1] [] -------------------------------------------------------------- -------------------------------------------------------------- head <--> 0[0] <--> 3[3] <--> 1[1] <--> tail cache: 0:3[3] 0:0[0] 1:1[1] [] -------------------------------------------------------------- -------------------------------------------------------------- head <--> 4[4] <--> 0[0] <--> 3[3] <--> tail cache: 0:3[3] 0:0[0] 1:4[4] [] -------------------------------------------------------------- -------------------------------------------------------------- head <--> 2[2] <--> 4[4] <--> 0[0] <--> tail cache: 0:0[0] 1:4[4] 2:2[2] -------------------------------------------------------------- -------------------------------------------------------------- head <--> 4[4] <--> 2[2] <--> 0[0] <--> tail cache: 0:0[0] 1:4[4] 2:2[2] --------------------------------------------------------------
可以看到,第2,5,7 次put出现了hit,每次hit正常调整了优先级,其他6次 put出现fault,则新增节点并踢出最旧的数据
ref: "LRU Cache - Complete Tutorial"
这里给出数据如下
Let's suppose we have an LRU cache of capacity 3, and we would like to perform the following operations: put (key=1, value=A) into the cache put (key=2, value=B) into the cache put (key=3, value=C) into the cache get (key=2) from the cache get (key=4) from the cache put (key=4, value=D) into the cache put (key=3, value=E) into the cache get (key=4) from the cache put (key=1, value=A) into the cache
其执行流程理应如下
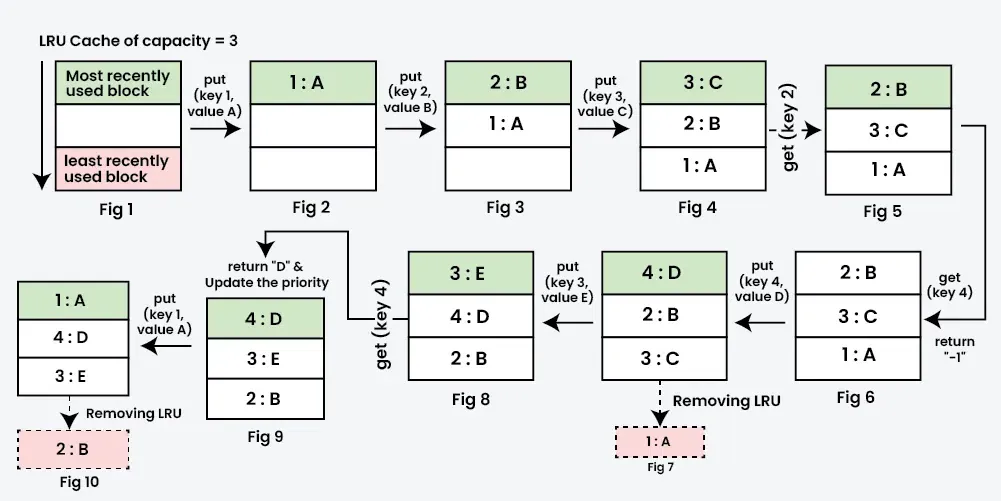
实际测试结果如下
-------------------------------------------------------------- head <--> 1[100] <--> tail cache: [] 1:1[100] [] -------------------------------------------------------------- -------------------------------------------------------------- head <--> 2[200] <--> 1[100] <--> tail cache: [] 1:1[100] 2:2[200] -------------------------------------------------------------- -------------------------------------------------------------- head <--> 3[300] <--> 2[200] <--> 1[100] <--> tail cache: 0:3[300] 1:1[100] 2:2[200] -------------------------------------------------------------- lru_get key=2 value=200 -------------------------------------------------------------- head <--> 2[200] <--> 3[300] <--> 1[100] <--> tail cache: 0:3[300] 1:1[100] 2:2[200] -------------------------------------------------------------- lru_get key=4 value=-1 -------------------------------------------------------------- head <--> 2[200] <--> 3[300] <--> 1[100] <--> tail cache: 0:3[300] 1:1[100] 2:2[200] -------------------------------------------------------------- -------------------------------------------------------------- head <--> 4[400] <--> 2[200] <--> 3[300] <--> tail cache: 0:3[300] 1:4[400] 2:2[200] -------------------------------------------------------------- -------------------------------------------------------------- head <--> 3[500] <--> 4[400] <--> 2[200] <--> tail cache: 0:3[500] 1:4[400] 2:2[200] -------------------------------------------------------------- lru_get key=4 value=400 -------------------------------------------------------------- head <--> 4[400] <--> 3[500] <--> 2[200] <--> tail cache: 0:3[500] 1:4[400] 2:2[200] -------------------------------------------------------------- -------------------------------------------------------------- head <--> 1[100] <--> 4[400] <--> 3[500] <--> tail cache: 0:3[500] 1:1[100] 1:4[400] [] --------------------------------------------------------------
我将步骤按条列出,可以和上述图片对应
- put 1:100
- put 2:200
- put 3:300,当前链表状态 3-2-1
- get 2, 此时将节点2设置为链表头,此时链表状态 2-3-1
- get 4,此时将节点4不存在,返回-1,此时链表状态 2-3-1
- put 4:400,此时链表状态 4-2-3
- put 3:500,此时链表状态 3-4-2
- get 4,此时链表状态 4-3-2
- put 1:100,此时链表状态 1-4-3
压力测试7x24
压力测试比较简单,长期测试下,观测lru是否出现错误的链表和错误的slots即可,同时没有内存泄漏 这里假设capacity为4,slots等于capacity的情况下压力测试,每100000us进行put一次,随机get,put和get的key和value也是随机的。其代码如下
lru_cache = lru_create(4, 4); while(1){ lru_put_and_print(lru_cache, get_random(), get_random()); if(get_random() % 10 == 0) lru_get_and_print(lru_cache, get_random()); usleep(100000); } lru_destory(lru_cache);
7x24小时下,内存不增长
2647919 root 20 0 1924 424 360 S 0.0 0.0 0:00.00 lru
数据均正常
-------------------------------------------------------------- head <--> 181[112] <--> 125[161] <--> 67[166] <--> 204[251] <--> tail cache: 0:204[251] 1:181[112] 1:125[161] [] 3:67[166] -------------------------------------------------------------- -------------------------------------------------------------- head <--> 236[120] <--> 181[112] <--> 125[161] <--> 67[166] <--> tail cache: 0:236[120] 1:181[112] 1:125[161] [] 3:67[166] -------------------------------------------------------------- -------------------------------------------------------------- head <--> 141[150] <--> 236[120] <--> 181[112] <--> 125[161] <--> tail cache: 0:236[120] 1:141[150] 1:181[112] 1:125[161] [] [] -------------------------------------------------------------- -------------------------------------------------------------- head <--> 150[95] <--> 141[150] <--> 236[120] <--> 181[112] <--> tail cache: 0:236[120] 1:141[150] 1:181[112] 2:150[95] [] --------------------------------------------------------------
总结
至此,已经通过充分验证的LRU的C语言版本完成了,就这样度过了一个愉快的周末。
参考文献
https://www.geeksforgeeks.org/dsa/design-a-data-structure-for-lru-cache/
https://www.geeksforgeeks.org/system-design/lru-cache-implementation/
https://www.geeksforgeeks.org/operating-systems/page-replacement-algorithms-in-operating-systems/
https://www.scaler.com/topics/lru-page-replacement-algorithm/