目录
上一个文章参考了网络的文章实战部署了qwen3 8b的llm模型,进一步的本文继续参考网络资源,上手在orin上部署stable diffusion
jetson ai lab
nvidia有一个ai lab,可以游玩很多的ai相关内容
本文主要实战部署stable-diffusion,所以参考文档如下
https://www.jetson-ai-lab.com/tutorial_stable-diffusion.html
可以看到,这里面会使用jetson containers的git仓库,先进去浏览一番
可以看到这个仓库有很多的ai示例可以尝试
这里找到stable diffusion的示例,其实际上是拉取了docker hub的容器镜像,如下
可以看到当前最新的版本是r36.4.0
下面开始根据文档的步骤演示运行stable-diffusion-webui
实战
首先国内的docker需要设置一下proxy。
# mkdir -p /etc/systemd/system/docker.service.d # cat /etc/systemd/system/docker.service.d/http-proxy.conf [Service] Environment="HTTP_PROXY=http://127.0.0.1:9981" Environment="HTTPS_PROXY=http://127.0.0.1:9981" # systemctl daemon-reload # systemctl restart docker
这里不同的proxy换成不同端口即可。
然后按照文档,这里尝试安装最新的版本r36.4.0,如下
# jetson-containers run dustynv/stable-diffusion-webui:r36.4.0
但是发现此版本的python的numpy要求,venv无法提供,所以降级版本到r36.2.0,如下
# jetson-containers run dustynv/stable-diffusion-webui:r36.2.0
因为在国内,所以默认模型下载不了,这是安装上述配置挂上代理后下载的。
下载完成之后,运行后发现docker的运行参数是如下
docker run --runtime nvidia --env NVIDIA_DRIVER_CAPABILITIES=compute,utility,graphics -it --rm --network host --shm-size=8g --volume /root/jetson-containers/jetson-containers/packages/diffusion/stable-diffusion-webui/openai/:/opt/stable-diffusion-webui/openai/ --volume /tmp/argus_socket:/tmp/argus_socket --volume /etc/enctune.conf:/etc/enctune.conf --volume /etc/nv_tegra_release:/etc/nv_tegra_release --volume /tmp/nv_jetson_model:/tmp/nv_jetson_model --volume /var/run/dbus:/var/run/dbus --volume /var/run/avahi-daemon/socket:/var/run/avahi-daemon/socket --volume /var/run/docker.sock:/var/run/docker.sock --volume /root/jetson-containers/jetson-containers/data:/data -v /etc/localtime:/etc/localtime:ro -v /etc/timezone:/etc/timezone:ro --device /dev/snd --device /dev/bus/usb --device /dev/i2c-0 --device /dev/i2c-1 --device /dev/i2c-2 --device /dev/i2c-4 --device /dev/i2c-5 --device /dev/i2c-7 --device /dev/i2c-9 -v /run/jtop.sock:/run/jtop.sock --name jetson_container_20250910_222642 dustynv/stable-diffusion-webui:r36.2.0
第一个问题出现了,容器内的模型无法下载,这里观察到默认的data在/root/jetson-containers/jetson-containers/data上,如下
--volume /root/jetson-containers/jetson-containers/data:/data
所以进入目录手动下载模型到指定目录,如下
# cd /root/jetson-containers/jetson-containers/data/models/stable-diffusion/models/Stable-diffusion # wget https://huggingface.co/runwayml/stable-diffusion-v1-5/resolve/main/v1-5-pruned-emaonly.safetensors
下载后继续尝试运行,发现CLIPTokenizer无法加载,日志如下
Python 3.10.12 (main, Jun 11 2023, 05:26:28) [GCC 11.4.0] Version: v1.7.0 Commit hash: cf2772fab0af5573da775e7437e6acdca424f26e Launching Web UI with arguments: --data=/data/models/stable-diffusion --enable-insecure-extension-access --xformers --listen --port=7860 Style database not found: /data/models/stable-diffusion/styles.csv Loading weights [6ce0161689] from /data/models/stable-diffusion/models/Stable-diffusion/v1-5-pruned-emaonly.safetensors /opt/stable-diffusion-webui/extensions-builtin/stable-diffusion-webui-tensorrt/ui_trt.py:64: GradioDeprecationWarning: The `style` method is deprecated. Please set these arguments in the constructor instead. with gr.Row().style(equal_height=False): Running on local URL: http://0.0.0.0:7860 To create a public link, set `share=True` in `launch()`. Startup time: 15.5s (prepare environment: 3.1s, import torch: 4.8s, import gradio: 1.9s, setup paths: 1.5s, initialize shared: 0.2s, other imports: 1.3s, setup codeformer: 0.1s, load scripts: 0.9s, create ui: 0.9s, gradio launch: 0.8s). Creating model from config: /opt/stable-diffusion-webui/configs/v1-inference.yaml /opt/stable-diffusion-webui/openai/clip-vit-large-patch14 creating model quickly: OSError Traceback (most recent call last): File "/usr/lib/python3.10/threading.py", line 973, in _bootstrap self._bootstrap_inner() File "/usr/lib/python3.10/threading.py", line 1016, in _bootstrap_inner self.run() File "/usr/lib/python3.10/threading.py", line 953, in run self._target(*self._args, **self._kwargs) File "/opt/stable-diffusion-webui/modules/initialize.py", line 147, in load_model shared.sd_model # noqa: B018 File "/opt/stable-diffusion-webui/modules/shared_items.py", line 128, in sd_model return modules.sd_models.model_data.get_sd_model() File "/opt/stable-diffusion-webui/modules/sd_models.py", line 531, in get_sd_model load_model() File "/opt/stable-diffusion-webui/modules/sd_models.py", line 634, in load_model sd_model = instantiate_from_config(sd_config.model) File "/opt/stable-diffusion-webui/repositories/stable-diffusion-stability-ai/ldm/util.py", line 89, in instantiate_from_config return get_obj_from_str(config["target"])(**config.get("params", dict())) File "/opt/stable-diffusion-webui/repositories/stable-diffusion-stability-ai/ldm/models/diffusion/ddpm.py", line 563, in __init__ self.instantiate_cond_stage(cond_stage_config) File "/opt/stable-diffusion-webui/repositories/stable-diffusion-stability-ai/ldm/models/diffusion/ddpm.py", line 630, in instantiate_cond_stage model = instantiate_from_config(config) File "/opt/stable-diffusion-webui/repositories/stable-diffusion-stability-ai/ldm/util.py", line 89, in instantiate_from_config return get_obj_from_str(config["target"])(**config.get("params", dict())) File "/opt/stable-diffusion-webui/repositories/stable-diffusion-stability-ai/ldm/modules/encoders/modules.py", line 103, in __init__ self.tokenizer = CLIPTokenizer.from_pretrained(version) File "/usr/local/lib/python3.10/dist-packages/transformers/tokenization_utils_base.py", line 1809, in from_pretrained raise EnvironmentError( OSError: Can't load tokenizer for 'openai/clip-vit-large-patch14'. If you were trying to load it from 'https://huggingface.co/models', make sure you don't have a local directory with the same name. Otherwise, make sure 'openai/clip-vit-large-patch14' is the correct path to a directory containing all relevant files for a CLIPTokenizer tokenizer.
根据日志初步怀疑也是docker内的环境拿到openai/clip-vit-large-patch14,所以也是手动下载
# cd /root/jetson-containers/jetson-containers/packages/diffusion/stable-diffusion-webui # mkdir openai && cd openai # apt install git-lfs # git clone https://huggingface.co/openai/clip-vit-large-patch14
经过漫长的等待,终于拉取了其13G的模型内容,如下
# cd /root/jetson-containers/jetson-containers/packages/diffusion/stable-diffusion-webui/openai/clip-vit-large-patch14 .
到这里还需要判断和分享一下日志报错的情况
这里根据报错的日志,看到launch.py的运行参数是如下
Launching Web UI with arguments: --data=/data/models/stable-diffusion --enable-insecure-extension-access --xformers --listen --port=7860
所以其实际运行的命令可能是如下
# python3 launch.py --data=/data/models/stable-diffusion --enable-insecure-extension-access --xformers --listen --port=7860
根据python的堆栈可以知道代码出错在/usr/local/lib/python3.10/dist-packages/transformers/tokenization_utils_base.py的1809行,进入确认一下,找到from_pretrained函数的声明,如下
def from_pretrained(cls, pretrained_model_name_or_path: Union[str, os.PathLike], *init_inputs, **kwargs):
可以看到,这是pretrained_model_name_or_path: Union[str, os.PathLike]计算的路径,而pretrained_model_name_or_path可以从如下确认
File "/opt/stable-diffusion-webui/repositories/stable-diffusion-stability-ai/ldm/modules/encoders/modules.py", line 103, in __init__ self.tokenizer = CLIPTokenizer.from_pretrained(version)
继续查看modules.py,确认version的值
def __init__(self, version="openai/clip-vit-large-patch14", device="cuda", max_length=77, freeze=True, layer="last", layer_idx=None): # clip-vit-base-patch32
合理猜测需要的路径实际上应该是容器里这个位置
/opt/stable-diffusion-webui/openai/clip-vit-large-patch14
为了保险,这里打上python的print再确认一遍,这里在from_pretrained打印pretrained_model_name_or_path的值,如下
print(os.path.abspath(pretrained_model_name_or_path))
手动运行,得到print打印,如下
# python3 launch.py --data=/data/models/stable-diffusion --enable-insecure-extension-access --xformers --listen --port=7860 /opt/stable-diffusion-webui/openai/clip-vit-large-patch14
猜测完全正确,需要在/opt/stable-diffusion-webui有对应的目录,现在返回去看docker run的参数,可以发现,/opt/stable-diffusion-webui并不是对外挂载的,所以需要新增一条volume参数,将之前下载的模型位置挂载到docker的这个目录上,如下
--volume /root/jetson-containers/jetson-containers/packages/diffusion/stable-diffusion-webui/openai/:/opt/stable-diffusion-webui/openai/
所以总的运行命令如下
docker run --runtime nvidia --env NVIDIA_DRIVER_CAPABILITIES=compute,utility,graphics -it --rm --network host --shm-size=8g --volume /root/jetson-containers/jetson-containers/packages/diffusion/stable-diffusion-webui/openai/:/opt/stable-diffusion-webui/openai/ --volume /tmp/argus_socket:/tmp/argus_socket --volume /etc/enctune.conf:/etc/enctune.conf --volume /etc/nv_tegra_release:/etc/nv_tegra_release --volume /tmp/nv_jetson_model:/tmp/nv_jetson_model --volume /var/run/dbus:/var/run/dbus --volume /var/run/avahi-daemon/socket:/var/run/avahi-daemon/socket --volume /var/run/docker.sock:/var/run/docker.sock --volume /root/jetson-containers/jetson-containers/data:/data -v /etc/localtime:/etc/localtime:ro -v /etc/timezone:/etc/timezone:ro --device /dev/snd --device /dev/bus/usb --device /dev/i2c-0 --device /dev/i2c-1 --device /dev/i2c-2 --device /dev/i2c-4 --device /dev/i2c-5 --device /dev/i2c-7 --device /dev/i2c-9 -v /run/jtop.sock:/run/jtop.sock --name jetson_container_20250910_222642 dustynv/stable-diffusion-webui:r36.2.0
此时运行日志如下
Python 3.10.12 (main, Jun 11 2023, 05:26:28) [GCC 11.4.0] Version: v1.7.0 Commit hash: cf2772fab0af5573da775e7437e6acdca424f26e Launching Web UI with arguments: --data=/data/models/stable-diffusion --enable-insecure-extension-access --xformers --listen --port=7860 Style database not found: /data/models/stable-diffusion/styles.csv Loading weights [6ce0161689] from /data/models/stable-diffusion/models/Stable-diffusion/v1-5-pruned-emaonly.safetensors /opt/stable-diffusion-webui/extensions-builtin/stable-diffusion-webui-tensorrt/ui_trt.py:64: GradioDeprecationWarning: The `style` method is deprecated. Please set these arguments in the constructor instead. with gr.Row().style(equal_height=False): Running on local URL: http://0.0.0.0:7860 To create a public link, set `share=True` in `launch()`. Startup time: 18.2s (prepare environment: 3.4s, import torch: 5.6s, import gradio: 2.2s, setup paths: 1.7s, initialize shared: 0.3s, other imports: 1.8s, setup codeformer: 0.2s, load scripts: 1.1s, create ui: 0.9s, gradio launch: 0.8s). Creating model from config: /opt/stable-diffusion-webui/configs/v1-inference.yaml Applying attention optimization: xformers... done. Model loaded in 10.8s (load weights from disk: 2.2s, create model: 0.8s, apply weights to model: 6.5s, apply half(): 0.2s, load textual inversion embeddings: 0.6s, calculate empty prompt: 0.3s).
没有看到报错了,同时可以看到默认开放端口在0.0.0.0:7860,所以可以同一网络环境下打开这个页面,做一下尝试.
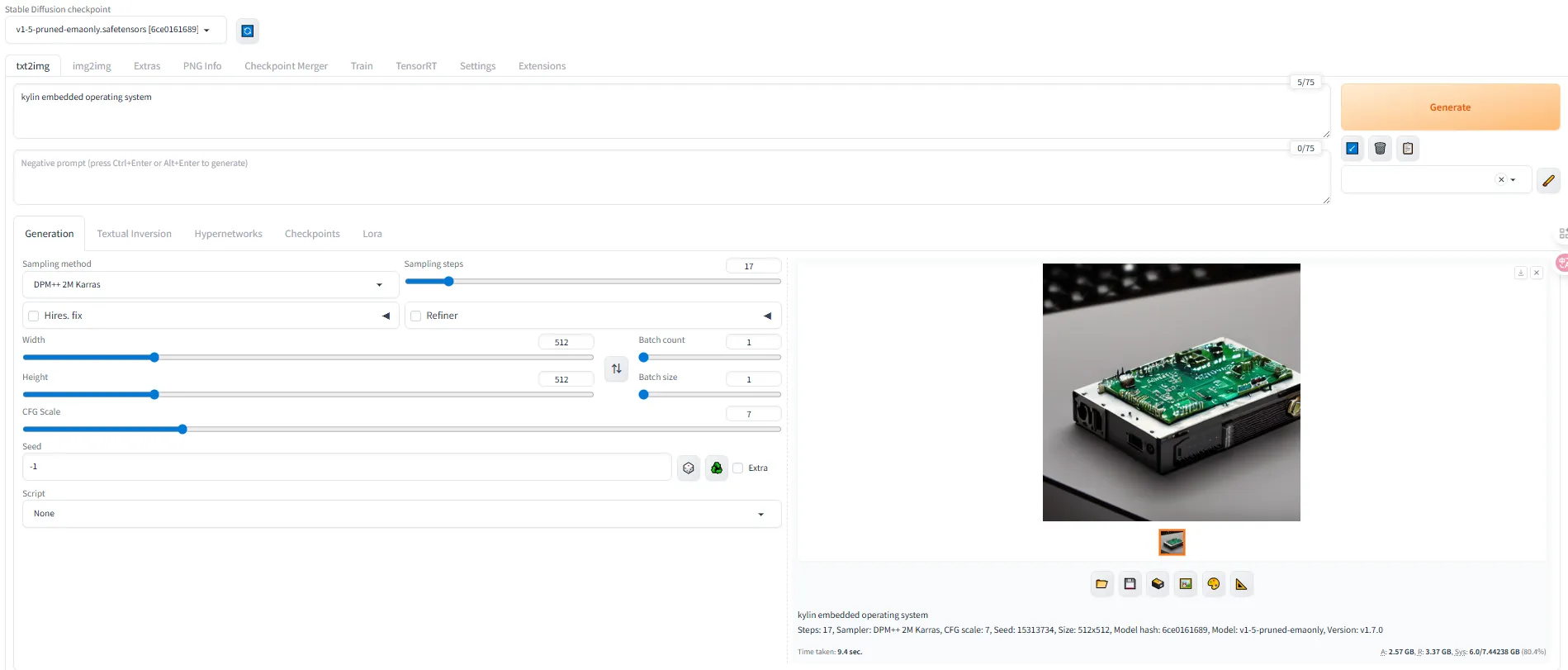
这里简单生成了一下麒麟嵌入式系统的图片,还是比较准确的,如下。
再生成一张,查看一下gpu占用情况
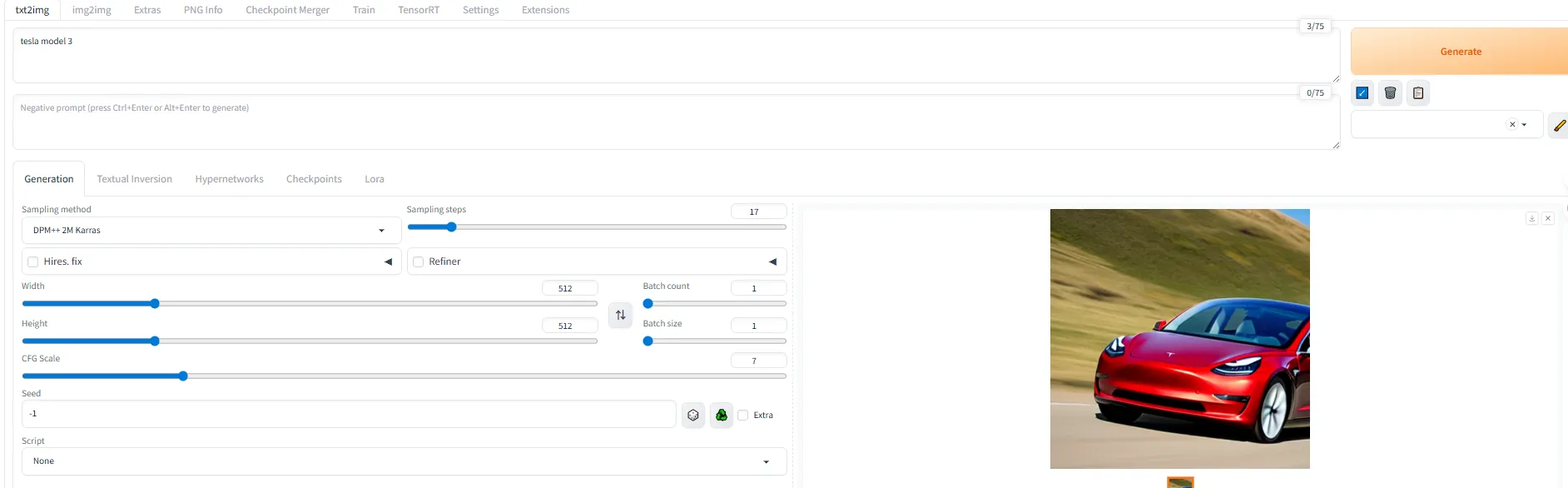

可以看到,内存5个多G,GPU全跑,整体比qwen3 8b要顺利很多,orin nano运行stable diffusion 并不是很吃力。
最后,其实jetson-ai-lab的文档也告诉你了,容器是这样如下运行的,
cd /opt/stable-diffusion-webui && python3 launch.py \ --data=/data/models/stable-diffusion \ --enable-insecure-extension-access \ --xformers \ --listen \ --port=7860
参考
https://www.jetson-ai-lab.com/tutorial_stable-diffusion.html
https://zhuanlan.zhihu.com/p/1889443308834624504
总结
本次参考网络资源实战了stable diffusion,相比于ollma,因为是容器运行,所以代理的问题比较难搞,但是总归来说有办法的,整体还是非常轻松能够跑起来的。使用两个小时下来,orin 发热不严重,完全满足可以长期运行。