目录
这两天qwen推出了max模型,是qwen平台最强的大模型,短暂尝新了一下。
想到自己jetson也能够运行本地模型,遂基于jetson orin nano,运行了qwen3 8b在设备上。本文介绍qwen3 8b运行步骤
qwen3 max
qwen3 max的网页版如下
简单问了一个问题:
可以看到,这里使用了open-webui搭建的。
qwen3 8b安装步骤
根据上面的启发,打算使用ollama搭建qwen3 8b,然后使用open-webui将其运行起来尝试,不知道能不能跑得动。
下载ollma
参阅官网说明https://ollama.com/download/linux,直接下载即可
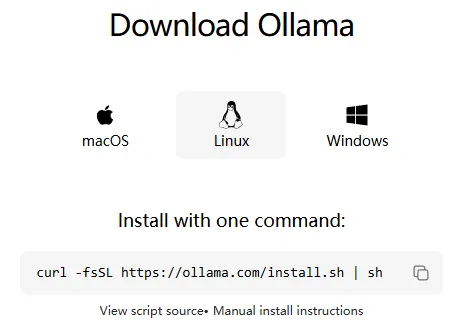
curl -fsSL https://ollama.com/install.sh | sh
下载模型
然后进入qwen3选择对应的模型,这里我选择8b,所以如下使用
ollama run qwen3:8b
上面两步需要等很久,大概1小时。完成之后,可以ollma查看当前系统存在什么模型
root@kylin:~# ollama list NAME ID SIZE MODIFIED qwen3:8b 500a1f067a9f 5.2 GB 2 hours ago
此时可以看到ollama默认启动端口在11434,如下
tcp6 0 0 localhost:11434 [::]:* LISTEN 12054/ollama
值得注意的是,这里是localhost,所以其他设备无法访问,所以需要开放一下,如下
# jetson_clocks # OLLAMA_HOST=0.0.0.0 OLLAMA_MODELS=/usr/share/ollama/.ollama/models /usr/local/bin/ollama serve
修改后端口如下显示
tcp6 0 0 [::]:11434 [::]:* LISTEN 306996/ollama
curl验证一下
# curl 0.0.0.0:11434 Ollama is running
qwen3正常运行,下面稍微演示一下效果
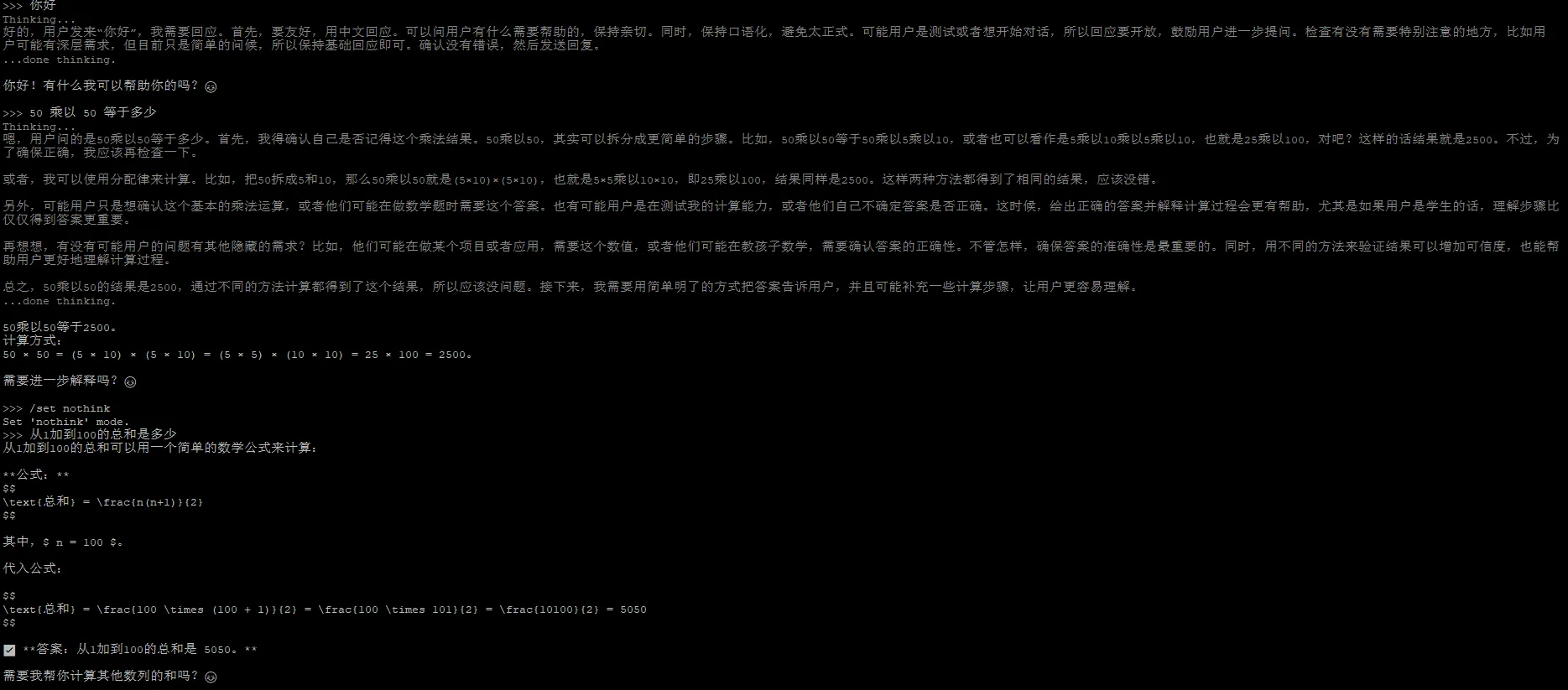
安装open-webui
为了网页上使用qwen3模型,这里使用open-webui。
但是在安装之前,有个小坑。
我们jetson的环境默认python3是3.10,而open-webui是3.11的要求,所以直接venv的环境不满足要求,需要conda重新创建一个python3.11的环境,如下
# conda create -n openwebui python=3.11
创建完成之后,激活此环境,运行open-webui
# conda activate openwebui # open-webui serve
完成之后,直接登录即可
http://ip:8080/
随便注册一个管理员账号。随便问一下如下

jtop信息
可以看到,nano的GPU已经跑满了。8b对于orin来说还是很吃力的。

参考
总结
今天看新闻发布了qwen3 max,遂来兴趣实战了一下orin上的ollama,根据上面的办法,ollama的其他模型都可以运行,而orin的板子主要还是服务嵌入式评估,所以跑不了多大的模型,8b已经很吃力了。比8b小模型拿orin跑应该就没问题了。