目录
之前几个文章把几个热门的模型都在orin上跑起来试用了一下,分别是 qwen3,diffusion,yolo,这是嵌入式项目中很常见实际应用,现在再基于jetson ai lab的tutorial,实战一下rag,关于rag我这里直接使用jetson开源的rag来实战,而不是通用的llamaindex。当然jetson ai lab的教程也有llamaindex的示例。
安装
默认copilot需要chromium和docker安装,这个之前的文章就已经安装好了,这里直接运行即可
# ./launch_jetson_copilot.sh
启动日志如下
Status: Downloaded newer image for dustynv/jetson-copilot:r36.4.0 Starting ollama server Couldn't find '/root/.ollama/id_ed25519'. Generating new private key. Your new public key is: ssh-ed25519 AAAAC3NzaC1lZDI1NTE5AAAAIGy9+RxSNWAVS6zF32ZnHVF/LSr0I+pCnwmhtbZx6a2y 2025/09/11 09:09:42 routes.go:1158: INFO server config env="map[CUDA_VISIBLE_DEVICES: GPU_DEVICE_ORDINAL: HIP_VISIBLE_DEVICES: HSA_OVERRIDE_GFX_VERSION: HTTPS_PROXY: HTTP_PROXY: NO_PROXY: OLLAMA_DEBUG:false OLLAMA_FLASH_ATTENTION:false OLLAMA_GPU_OVERHEAD:0 OLLAMA_HOST:http://0.0.0.0:11434 OLLAMA_INTEL_GPU:false OLLAMA_KEEP_ALIVE:5m0s OLLAMA_LLM_LIBRARY: OLLAMA_LOAD_TIMEOUT:5m0s OLLAMA_MAX_LOADED_MODELS:0 OLLAMA_MAX_QUEUE:512 OLLAMA_MODELS:/data/models/ollama/models OLLAMA_MULTIUSER_CACHE:false OLLAMA_NOHISTORY:false OLLAMA_NOPRUNE:false OLLAMA_NUM_PARALLEL:0 OLLAMA_ORIGINS:[http://localhost https://localhost http://localhost:* https://localhost:* http://127.0.0.1 https://127.0.0.1 http://127.0.0.1:* https://127.0.0.1:* http://0.0.0.0 https://0.0.0.0 http://0.0.0.0:* https://0.0.0.0:* app://* file://* tauri://*] OLLAMA_SCHED_SPREAD:false OLLAMA_TMPDIR: ROCR_VISIBLE_DEVICES: http_proxy: https_proxy: no_proxy:]" time=2025-09-11T09:09:42.176Z level=INFO source=images.go:754 msg="total blobs: 0" time=2025-09-11T09:09:42.176Z level=INFO source=images.go:761 msg="total unused blobs removed: 0" time=2025-09-11T09:09:42.176Z level=INFO source=routes.go:1205 msg="Listening on [::]:11434 (version 0.0.0)" time=2025-09-11T09:09:42.177Z level=INFO source=common.go:135 msg="extracting embedded files" dir=/tmp/ollama1274236136/runners time=2025-09-11T09:09:43.569Z level=INFO source=common.go:49 msg="Dynamic LLM libraries" runners="[cpu cuda_v12]" time=2025-09-11T09:09:43.570Z level=INFO source=gpu.go:199 msg="looking for compatible GPUs" time=2025-09-11T09:09:43.579Z level=WARN source=gpu.go:669 msg="unable to locate gpu dependency libraries" time=2025-09-11T09:09:43.579Z level=WARN source=gpu.go:669 msg="unable to locate gpu dependency libraries" time=2025-09-11T09:09:43.579Z level=WARN source=gpu.go:669 msg="unable to locate gpu dependency libraries" time=2025-09-11T09:09:43.699Z level=INFO source=types.go:107 msg="inference compute" id=GPU-d03db7ac-e66d-56fe-ae22-93568383bf53 library=cuda variant=jetpack6 compute=8.7 driver=12.6 name=Orin total="7.4 GiB" available="5.6 GiB" OLLAMA_MODELS /data/models/ollama/models OLLAMA_LOGS /data/logs/ollama.log ollama server is now started, and you can run commands here like 'ollama run llama3' Collecting usage statistics. To deactivate, set browser.gatherUsageStats to false. You can now view your Streamlit app in your browser. Local URL: http://localhost:8501 Network URL: http://192.168.31.55:8501 External URL: http://hide:8501
登录这个链接看到如下

可以看到正在下载llama3模型,其实之前的文章我们本地已经下载ollama并安装了qwen3了,但是这里因为是容器,其实llm相关的动作又重新做了一遍。
因为是跟着tutorial在实战,尽量还是不要自己去发挥。等一会儿就好,完成之后,显示如下
完成之后,回到主页面可以开始提问

演示
为了实践RAG,我以最近在阅读的Linux memory manager的pdf作为rag的文库,导入到RAG中,然后不使用rag和使用rag来对比,如下
点击Build a new index,这里起名是LMM
然后进入docker容器内部,准备上传文档
# docker exec -it kind_blackburn /bin/bash # mkdir /opt/jetson_copilot/Documents/LMM # scp root@kylin:~/_EA_Linux_Memory_Manager_21025.pdf .
然后在网页的Local documents选中LMM目录,可以看到需要新增一个文档,点击Build index
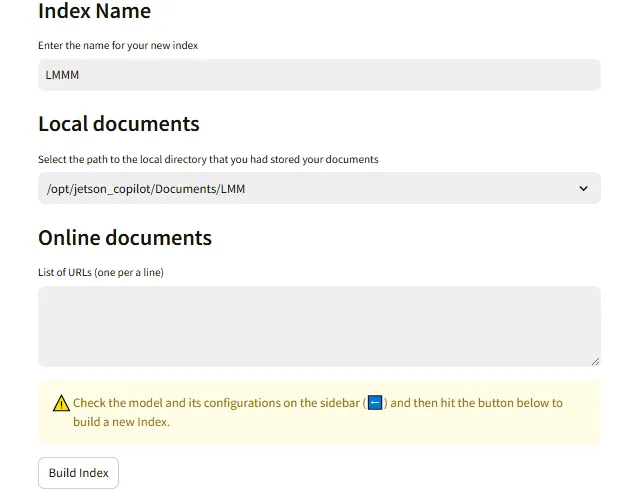
等待其生成index完成之后,回到主页面可以开始使用了。这里以linux内核的内存规整作为提问来测试rag的作用。
下面是不使用rag的问答

可以看到,这个回答没有技术细节。接下来使用带上Linux Memory Manager书籍的RAG问答

可以看到,这次回答引用了LMM书上的内容,并提供了部分代码细节
总结
本文基于Copilot进行了实战,通过容器运行了llama3大语言模型,然后加载LMM书籍作为RAG的素材,生成index后,对比了使用rag和不使用rag的效果。可以发现rag作为团队或个人的内部知识库还是很不错的。