目录
我们自己使用的服务器,经常需要编译代码等操作,并且是多人并行使用的服务器状态,使用久了的情况下,服务器经常会出现如下问题。
- OOM
- 卡死
- 短时间无响应
- 无法申请内存
- 编译代码缓慢
对于我这么多年使用服务器的经验而言,其实一直都是在平衡上面五个问题的状态,让其在上面五个问题中间得到平衡,而不因为某个点导致服务器的性能下降。
可见对于不同场景的服务器,需要为其设置不同的内存调节状态,本文基于编译型服务器,提出关于内存调节的一下想法和见解。这会对使用服务器有更好的理解。
只有拥有一个调教好的服务器,才能发挥利用服务器发挥自己最大的工作效率
默认的swap配置
linux默认配置swappiness是60,通常情况下,这个值的范围是0-100,值越高,则回收的时候优先选择匿名页,然后将匿名页搬运到swap分区中,值越低,会减少swap的使用,从而由其他参数调节page cache的行为
为什么首先谈这个呢。根据上面理解的,swappiness默认是60,那么从某种平衡上来看,如果系统存在内存压力的情况下,会稍微将anon page移到swap 分区中。那么将anon page移到swap 分区因为IO带来的性能损失和延迟对绝大部分人是能够接收的,这样就不至于可能出现系统完全无内存导致的oom情况。
根据默认值60,我们知道,linux内核考虑了很通用的情况下,牺牲一些性能从而满足内存在压力情况下的可用。
而面对服务器而言,特别是编译型服务器,我们每个编译任务可能是长时间,但一定会完成的,所以不希望移到swap分区,如果维持在60的值,大型任务例如llvm,chromium的构建就会很慢。所以需要降低swappiness的值
那我们设置swappiness的值是0还是1呢。根据长时间的经验来看,总结如下
- 当不开swap分区的情况下:更容易出现OOM
- 设置为0:当内存不足时,仍可能出现oom,只在内存非常低的情况下使用swap,且使用很少
- 设置为1:当内存不足时,还是会将部分anon page移动到swap,如果系统内存不足,不会立即oom,而是尽可能使用swap
可以看到,根据使用经验而言,swappiness在编译型服务器上,应该很低,但是如果设置为0,那么swap分区即使设置了很大,内核还是不会使用swap分区的空间,而是直接oom。那么推荐swappiness的值是1。当内存不够的时候,才将swap分区利用起来
根据swappiness的配置,我们能够解决默认情况下编译代码缓慢的问题,因为系统不再将anon page移动到swap 分区中了,也不会突然因为不当的swappiness设置导致oom情况出现,编译速度得到了加快。
drop_caches
根据上面的设置,系统默认不使用swap分区了,那么所有的任务都更倾向于使用内存了,对于很多人而言,都了解一个配置 drop_caches ,认为drop_caches能够通过定期任务减缓内存压力。
按照本人理解,其实 drop_caches 是清空page cache和slab cache
如果我们echo 1 > /proc/sys/vm/drop_caches那么情况的是page cache。 具体而言是清空处于inactive链表的page cache,实验如下:
未清空page cache如下
root@kylin:~# cat /proc/meminfo | grep -i active Active: 1361888 kB Inactive: 46626572 kB Active(anon): 843576 kB Inactive(anon): 387512 kB Active(file): 518312 kB Inactive(file): 46239060 kB
此时我们运行# echo 1 > /proc/sys/vm/drop_caches得到信息如下
root@kylin:~# cat /proc/meminfo | grep -i active Active: 1023844 kB Inactive: 438784 kB Active(anon): 862328 kB Inactive(anon): 368504 kB Active(file): 161516 kB Inactive(file): 170280 kB
可以看到,处于inactive上的46G内存得到了释放
接下来看drop_caches对slab的清空情况。首先我们知道slab的值是SReclaimable+SUnreclaim。而同样的drop_caches针对的是可回收的内存,也就是SReclaimable,而不是不可回收的内存SUnreclaim,演示如下
root@kylin:~# cat /proc/meminfo | grep -i slab -A 2 Slab: 3724284 kB SReclaimable: 3116412 kB SUnreclaim: 607872 kB root@kylin:~# echo 2 > /proc/sys/vm/drop_caches root@kylin:~# cat /proc/meminfo | grep -i slab -A 2 Slab: 602276 kB SReclaimable: 115296 kB SUnreclaim: 486980 kB
可以看到,对于SReclaimable对于的内存,得到了回收。
实际上,对于编译型服务器,这里更多是dentry cache,也就是文件系统访问缓存,我们演示一下如下
# cat /proc/sys/fs/dentry-state 97122 77478 45 0 53596 0 # echo 2 > /proc/sys/vm/drop_caches && cat /proc/sys/fs/dentry-state 17018 23 45 0 1065 0
可以看到,nr_unused从7万变为23了,内存从这里得到了释放
针对此,很多人,包括早期我自己也很喜欢定期执行 sync和drop_cachessync && echo 1 > /proc/sys/vm/drop_caches。 sync的目的是将脏页写回,这样可回收的内存就会变多。但是根据上面的了解,其缺点也很明显,针对编译型服务器,其dentry cache得到了错误的清除,导致编译速度变慢了,不仅如此,服务器还会出现概率卡死。
但实际上,如果我们了解内存的配置,其实无需定期执行,而是由kernel的self tuning。会比定期执行更好。
self tuning
根据上面提到的drop_caches,我们先讨论page caches的回收,这里借助lorenzo stoakes编写《the linux memory manager》一张图如下
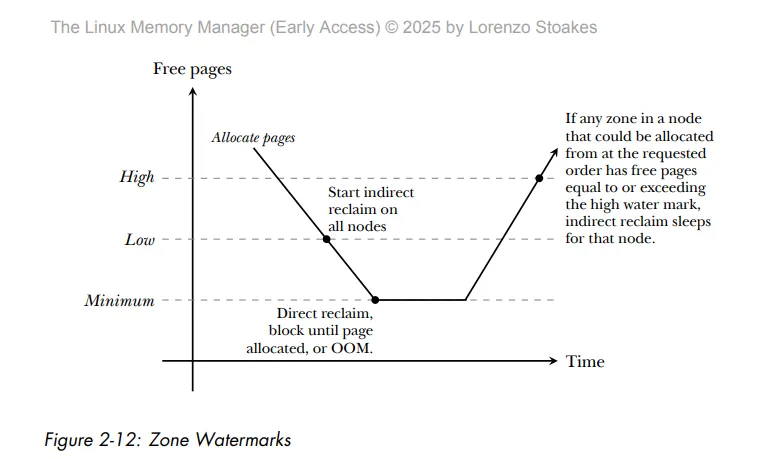
根据此图,可以看到很熟悉的一个机制,那就是linux 水位机制,这里简单回顾一下
- 当可用内存在水位low时,kswapd唤醒,开始非直接回收
- 当可用内存在水位min时,开启阻塞性的直接回收
- 如果此时内存剩余内存太小,或内存回收失败,则从进程列表中找到得分最低的进程oom杀掉。保障直接回收成功
- 当可用内存在水位high时,kswapd休眠
可以知道,如果内存压力太大,那么内核会自己回收内存,而不需要自己定期的drop_caches
其二,对于slab cache的self tuning方式,如下
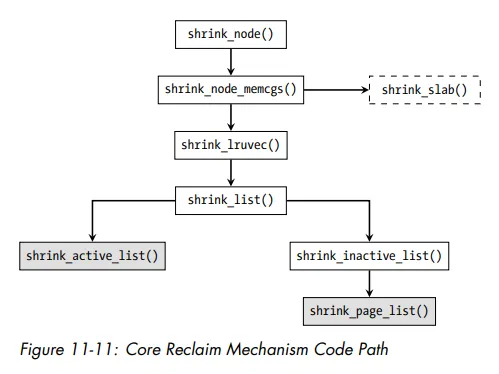
这里可以看到,slab默认的shrink机制能够自动回收slab cache。其机制也属于关于slab的indirect/direct reclaim回收,所以也符合水位机制。
调整self tuning
根据上面介绍的,我们可以针对性的调整水位的比例。
针对编译型服务器,根据多年的使用经验,那么可能出现如下问题
- 内存突然不足,直接可用内存到min以下,导致cc程序直接oom
- 内存申请和回收的生产者消费者不成比例,导致从low到min的速度很快,从而机器无响应
可以看到,默认的配置还是不满足编译型服务器,我们需要针对性的修改sysctl,如下
解决内存不足直接oom
对于min一下无可用内存,直接oom的情况,我们可以修改min_free_kbytes的值,通常min_free_kbytes的值也是内核通过当前所有zones的总和计算出来的,为了考虑常规情况,此值通常偏低了点,为了应对编译型服务器,那么需要设置高点,多高呢。我们可以对照内核的init_per_zone_wmark_min函数查看
int __meminit init_per_zone_wmark_min(void) { ...... min_free_kbytes = new_min_free_kbytes; if (min_free_kbytes < 128) min_free_kbytes = 128; if (min_free_kbytes > 262144) min_free_kbytes = 262144; ...... return 0; }
可以知道,内核最大可以设置到256M,鉴于我们是服务器,内存本身就很大,所以我们可以设置为256,如下
echo 262144 > /proc/sys/vm/min_free_kbytes
不过这个是根据实际情况,太大了也不一定好,个人建议设置到0.05%。也就是对于128G内存,设置到64M。
设置完了之后,可以长期监听vmstat的kswapd_low_wmark_hit_quickly 来判断你的服务器设置的值是否合理,如下
# cat /proc/vmstat | grep kswapd_low_wmark_hit_quickly kswapd_low_wmark_hit_quickly 358635
这个值代表kswapd到low水位的次数,这里我已经到358635次了。这里值得注意的是,这个次数不是越高越好,也不是越低越好。是根据情况查看增长速率,如下:
- 如果服务器任务较少,此值不应该快速上涨。否则服务器的内存设置有问题
- 如果服务器任务较多,此值不应该缓慢增长。否则服务器回收内存效率太低
这样,我们当内存不够的时候,我们就不会出现无法direct reclaim导致的oom情况了。
解决机器无响应
如果内存从low到min速度太快,又因为直接回收是阻塞的,所以我们经常发现服务器突然卡死了。 通常这种情况下,如果没有什么重要的事情,那么等一会儿就好了。
直接解决此问题的方式就是增加内存,例如32G的内存可以增加到128G,128G的内存可以增加到256G。
这里讨论的是既不想等一会儿自己恢复,又短时间无法增加服务器内存的情况。
针对这种情况,解决方案也很容易想到,我们扩大low到min的距离,也就是,假设min是64M,那我low是640M行不行呢?
很可惜的是,内核只提供了比例设置,不提供具体的值的设置。我们可以设置watermark_scale_factor来缓解这个问题
watermark_scale_factor控制了kswapd的主动性,默认其分母是10000,其值设置是10,那么是0.1%比率作为计算,也就是high与low的差距是总内存的0.1%。
针对此问题,缓解的方法是设置watermark_scale_factor大一点,具体多大呢,需要根据如下值的增长情况判断,
root@kylin:# cat /proc/vmstat |grep 'allocstall' allocstall_dma32 0 allocstall_normal 173606 allocstall_movable 4338981
这里arm64没有ZONE_DMA,不用奇怪,我们监控normal和movable的allocstall值,如果这个值变大,那么需要将watermark_scale_factor放大。
echo 40 > /proc/sys/vm/watermark_scale_factor
根据经验,调整watermark_scale_factor并不能改善无响应的问题,因为内存不够就是不够,只是改善进入直接回收的时机,也就是扩大水位线之间的差距,从而减少系统无响应的次数
overcommit
默认情况下,内核设置了overcommit_memory的值是0,意味着如果没有可用内存,则申请内存失败。它会影响到一些大型任务构建是否成功。
也就是说,有时候会因为内存不够,导致某些程序无法编译成功,所以有些情况下,我们需要设置overcommit_memory为1如下
echo 1 > /proc/sys/vm/overcommit_memory
这里含义如下
- OVERCOMMIT_GUESS:适度过度提交,当大块内存申请时会拒绝
- OVERCOMMIT_ALWAYS: 允许分配,后果自己负责
- ERCOMMIT_NEVER:不overcommit
值得注意的是,如果设置为1,那么可能会导致oom,理由可想而知。
脏页回收
上面已经说明清楚了内核关于内存的回收流程,但服务器的配置光内存的回收还不够,我们需要控制脏页的回收策略。
对于脏页的回收设置,有一个文章推荐设置具体的值,而不是比率。如下
所以我们设置脏页回收策略根据值来配置。
vm.dirty_ratio = 0 vm.dirty_bytes = 629145600 # keep the vm.dirty_background_bytes to approximately 50% of this setting vm.dirty_background_bytes = 314572800
值得注意的是默认情况下,设置的dirty_bytes是0,而dirty_ratio是20。所以对于编译型服务器而言,这里必须修改一下。
dentry的回收
上面可以看到slab的SReclaimable回收来源于dentry,因为我们是编译型服务器,所以我们需要调整vfs_cache_pressure。
vfs_cache_pressure的作用是回收文件系统缓存,如果我们内存吃紧,还容易出现OOM,那么就增高此值,如果内存足够,则降低此值。
为了让服务器能够编译,并且保留缓存,我更倾向于降低此值。
echo 50 > /proc/sys/vm/vfs_cache_pressure
如果你编译大型任务,发现出现OOM了,那么就增大此值
echo 500 > /proc/sys/vm/vfs_cache_pressure
总结
至此,我总结了这些年和服务器斗智斗勇的这些配置,在不同情况下,需要设置的不一样。 对于从事操作系统开发而言,成千上万的软件包要构建和开发,那么服务器就是纯编译型服务器,那么这种情况下针对内存情况的配置如下。
如果内存吃紧,那么如下配置
echo 1 > /proc/sys/vm/swappiness echo 262144 > /proc/sys/vm/min_free_kbytes echo 40 > /proc/sys/vm/watermark_scale_factor echo 1 > /proc/sys/vm/overcommit_memory echo 629145600 > /proc/sys/vm/dirty_bytes echo 314572800 > /proc/sys/vm/dirty_background_bytes echo 500 > /proc/sys/vm/vfs_cache_pressure
值得注意的是
- 256M内存作为min,取决于总内存大小
- 40的watermark_scale_factor只能改善无响应情况
- overcommit_memory设置为1可能导致OOM(取决于回收情况),但不会让任务编译失败
- 600M的dirty_bytes,取决于总内存大小
- vfs_cache_pressure用于积极回收slab caches
这样设置的情况下,编译任何工程都能工作
如果服务器内存本来就多,这个问题就变得简单了
1. 无需swap分区 2. 增大dirty_bytes 3. vfs_cache_pressure设置为1
当然,那不现实,写到这里,不禁发出感叹:
- 内存就像生活,富人无需思考琐碎,穷人才会步履维艰。
对于开头提到的问题解决效果呢,如下
- OOM : 改善
- 卡死: 解决
- 短时间无响应:改善
- 无法申请内存 :解决
- 编译代码缓慢 :解决