目录
mlock系统调用可以将进程的虚拟内存页面锁定在物理内存中,这个锁定会触发两个事情
- 第一个事情就是立马为内存区域申请物理内存。
- 第二个事情就是设置标志位,将其放到不可回收的lru链表,防止swap。
mlock实现原理
mlock的调用意味着,后续代码操作这块内存,无需触发缺页异常,并且如果系统在运行过程中,即使触发主动或被动内存回收,都不会迁移这段内存到swap空间上。从而保证了实时程序在内存访问时得低时延和高可靠性。下面简单理解一下上述两个步骤的具体实现。
主动分配内存,避免缺页异常
当系统调用mlock后,该函数通过系统调用下发到内核,其代码如下
SYSCALL_DEFINE2(mlock, unsigned long, start, size_t, len) { return do_mlock(start, len, VM_LOCKED); }
do_mlock函数进行参数检查和权限检查,并检查RLIMIT_MEMLOCK的值,如一切正常,则调用__mm_populate进行内存的填充。
static __must_check int do_mlock(unsigned long start, size_t len, vm_flags_t flags) { ...... error = __mm_populate(start, len, 0); if (error) return __mlock_posix_error_return(error); ...... return 0; }
__mm_populate 会通过find_vma找到start到start+len的vma区域,然后调用 populate_vma_page_range 来实际分配内存
int __mm_populate(unsigned long start, unsigned long len, int ignore_errors) { ...... for (nstart = start; nstart < end; nstart = nend) { if (!locked) { locked = 1; down_read(&mm->mmap_sem); vma = find_vma(mm, nstart); } else if (nstart >= vma->vm_end) vma = vma->vm_next; ...... ret = populate_vma_page_range(vma, nstart, nend, &locked); } nend = nstart + ret * PAGE_SIZE; }
populate_vma_page_range 会根据传入的vma结构体和页面的起始地址和结束地址,设置页面属性为FOLL_TOUCH(标记已访问),FOLL_POPULATE(触发缺页异常),FOLL_MLOCK(锁定防止swap),最终调用页面分配函数__get_user_pages。
long populate_vma_page_range(struct vm_area_struct *vma, unsigned long start, unsigned long end, int *nonblocking) { ...... gup_flags = FOLL_TOUCH | FOLL_POPULATE | FOLL_MLOCK; ...... return __get_user_pages(current, mm, start, nr_pages, gup_flags, NULL, NULL, nonblocking); }
这里__get_user_pages是内核默认页面申请函数,本文不讨论内存申请原理,故简化其调用流程如下
__get_user_pages ---> faultin_page ---> handle_mm_fault
至此,我们可以清楚的了解了mlock在设置了之后,会立马触发物理页面的分配。这样在后续使用这些页面的时候,无需再触发缺页异常,。
防止swap
下面继续讨论mlock的第二个事情,防止swap换出。 在讨论swap换出时,我们需要了解内核内存的回收机制,如下
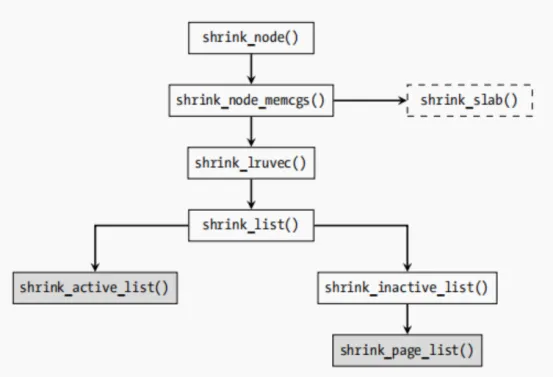
可以知道,内核的内存回收主要回收两个lru list,一个是active list,一个是inactive list。下面逐一介绍。
活跃链表
首先是shrink_active_list,其主要目的是处理活跃的lru链表,然后让其加入非活跃链表,主要通过反向映射机制查找这个物理页面对应的所有vma,然后确定mm flag,如果设置VM_LOCKED的vma 则退出反向映射,这样就不会被rmap统计上。
其代码如下,首先从shrink_active_list开始统计并回收active 链表的内存,如下
static void shrink_active_list(unsigned long nr_to_scan, struct lruvec *lruvec, struct scan_control *sc, enum lru_list lru) { ...... while (!list_empty(&l_hold)) { if (page_referenced(page, 0, sc->target_mem_cgroup, &vm_flags)) { list_add(&page->lru, &l_active); continue; } list_add(&page->lru, &l_inactive); } ...... }
可以看到,shrink_active_list的作用是将一些可以迁移的页面移动到inactive 链表上,这样尽可能的回收一些页面来释放内存,此时我们进一步关注page_referenced的实现,如下
int page_referenced(struct page *page, int is_locked, struct mem_cgroup *memcg, unsigned long *vm_flags) { ...... struct rmap_walk_control rwc = { .rmap_one = page_referenced_one, .arg = (void *)&pra, .anon_lock = page_lock_anon_vma_read, }; rmap_walk(page, &rwc); ...... return pra.referenced; }
这里page_referenced使用了rmap机制来查询每个页面的vma结构,其rmap的代码调用路径如下
.rmap_one = page_referenced_one, rmap_walk(page, &rwc); rmap_walk_ksm/rmap_walk_anon/rmap_walk_file rwc->rmap_one(page, vma, address, rwc->arg) == page_referenced_one page_vma_mapped_walk
此时我们关注page_referenced_one函数的处理,它会直接退出反向映射的统计,如下
static bool page_referenced_one(struct page *page, struct vm_area_struct *vma, unsigned long address, void *arg) { ...... while (page_vma_mapped_walk(&pvmw)) { address = pvmw.address; if (vma->vm_flags & VM_LOCKED) { page_vma_mapped_walk_done(&pvmw); pra->vm_flags |= VM_LOCKED; return false; /* To break the loop */ } } ...... }
可以看到,在处理活跃链表的时候,如果带有VM_LOCKED的vma,则直接退出反向映射,不再将其从活跃链表迁移到非活跃链表上。
非活跃链表
接下来看非活跃链表上关于VM_LOCKED的页面处理方式。也就是shrink_inactive_list函数,其做法就是从unactive 链表上取出一些 page 出来,然后尝试进行 回收,其代码如下
static noinline_for_stack unsigned long shrink_inactive_list(unsigned long nr_to_scan, struct lruvec *lruvec, struct scan_control *sc, enum lru_list lru) { ...... nr_taken = isolate_lru_pages(nr_to_scan, lruvec, &page_list, &nr_scanned, sc, lru); nr_reclaimed = shrink_page_list(&page_list, pgdat, sc, 0, &stat, false); free_unref_page_list(&page_list); ...... }
这里shrink_page_list 会调用 page_check_references 继而调用 page_referenced 进行rmap检查统计pte的引用,并同时检查VM_LOCKED。page_check_references的代码如下
static enum page_references page_check_references(struct page *page, struct scan_control *sc) { referenced_ptes = page_referenced(page, 1, sc->target_mem_cgroup, &vm_flags); if (vm_flags & VM_LOCKED) return PAGEREF_RECLAIM; ...... }
page_referenced 上面分析过了,会通过rmap机制找到每个vma,然后检查到有VM_LOCKED则跳出不统计。其简单流程如下
page_referenced ---> rmap_walk ---> rmap_walk_xxx ---> page_referenced_one
在page_referenced 之后,如果判断vma设置了VM_LOCKED标志位,则直接返回PAGEREF_RECLAIM,会由try_to_unmap 将其移动到 unevictable 链表
函数 shrink_page_list 会在 最后调用 try_to_unmap
下面先跟踪try_to_unmap的代码路径。
try_to_unmap ---> rmap_walk ---> rmap_walk_xxx ---> try_to_unmap_one
在 try_to_unmap_one 中会判断VM_LOCKED,然后调用mlock_vma_page,代码如下
static bool try_to_unmap_one(struct page *page, struct vm_area_struct *vma, unsigned long address, void *arg) { ...... if (vma->vm_flags & VM_LOCKED) { /* PTE-mapped THP are never mlocked */ if (!PageTransCompound(page)) { /* * Holding pte lock, we do *not* need * mmap_sem here */ mlock_vma_page(page); } ret = false; page_vma_mapped_walk_done(&pvmw); break; } } ...... }
mlock_vma_page 会设置page的PG_mlocked标志,然后隔离页面后将其放入不可移动链表,其代码如下
void mlock_vma_page(struct page *page) { if (!TestSetPageMlocked(page)) { count_vm_event(UNEVICTABLE_PGMLOCKED); if (!isolate_lru_page(page)) putback_lru_page(page); } }
到这里,mlock的第二个作用也介绍清楚了,操作系统在进行页面回收的过程中,分为两大部分,shrink_active_list和shrink_inactive_list。如果页面带有给VM_LOCKED标志,那么会主动退出回收流程,并将其加入到不可移动链表上,这样后续的所有swap流程都不会处理带有VM_LOCKED标志的页面。从而避免了内存回收。
测试mlock
下面通过测试程序来验证通过mlock加强实时程序的高确定性问题。
#include <stdio.h> #include <stdlib.h> #include <sys/mman.h> #include <time.h> #include <math.h> #define ARRAY_SIZE (1024 * 1024 * 100) #define ITERATIONS 1000 #define ACCESS_COUNT 10000 int* prepare_memory(int use_mlock) { int *array = (int *)malloc(ARRAY_SIZE * sizeof(int)); if (!array) { printf("malloc failed"); exit(EXIT_FAILURE); } int mlock_success = 0; if (use_mlock) { if (mlock(array, ARRAY_SIZE * sizeof(int)) != 0) { printf("Warning: mlock failed (may not be root or RLIMIT exceeded)\n"); } else { mlock_success = 1; } } return array; } double run_access_test(int *array) { struct timespec start, end; clock_gettime(CLOCK_MONOTONIC, &start); for (int i = 0; i < ACCESS_COUNT; i++) { array[(i * 1024) % ARRAY_SIZE] += i; } clock_gettime(CLOCK_MONOTONIC, &end); long long elapsed_ns = (end.tv_sec - start.tv_sec) * 1000000000LL + (end.tv_nsec - start.tv_nsec); return (double)elapsed_ns / 1000.0; } void calculate_stats(double *times, int count, double *min, double *max, double *avg, double *stddev) { *min = times[0]; *max = times[0]; double sum = 0.0; for (int i = 0; i < count; i++) { sum += times[i]; if (times[i] < *min) *min = times[i]; if (times[i] > *max) *max = times[i]; } *avg = sum / count; double variance_sum = 0.0; for (int i = 0; i < count; i++) { variance_sum += pow(times[i] - *avg, 2); } *stddev = sqrt(variance_sum / count); } int main() { double times_mlock[ITERATIONS]; double times_nomlock[ITERATIONS]; #define MLOCK 1 #define NOMLOCK 0 int *array_mlock = prepare_memory(MLOCK); int *array_nomlock = prepare_memory(NOMLOCK); for (int i = 0; i < ITERATIONS; i++) { times_mlock[i] = run_access_test(array_mlock); } for (int i = 0; i < ITERATIONS; i++) { times_nomlock[i] = run_access_test(array_nomlock); } free(array_mlock); free(array_nomlock); double min_mlock, max_mlock, avg_mlock, stddev_mlock; double min_nomlock, max_nomlock, avg_nomlock, stddev_nomlock; calculate_stats(times_mlock, ITERATIONS, &min_mlock, &max_mlock, &avg_mlock, &stddev_mlock); calculate_stats(times_nomlock, ITERATIONS, &min_nomlock, &max_nomlock, &avg_nomlock, &stddev_nomlock); printf("With mlock:\n"); printf(" Min: %.2f μs | Max: %.2f μs | Avg: %.2f μs | StdDev: %.2f μs\n", min_mlock, max_mlock, avg_mlock, stddev_mlock); printf("Without mlock:\n"); printf(" Min: %.2f μs | Max: %.2f μs | Avg: %.2f μs | StdDev: %.2f μs\n", min_nomlock, max_nomlock, avg_nomlock, stddev_nomlock); return 0; }
将代码命令为mlock_test.c,编译后运行如下
gcc mlock_test.c -lm -o mlock_test ./mlock_test With mlock: Min: 436.62 μs | Max: 534.95 μs | Avg: 509.69 μs | StdDev: 22.37 μs Without mlock: Min: 491.31 μs | Max: 55170.11 μs | Avg: 585.05 μs | StdDev: 1410.62 μs
可以看到,通过测试,使用mlock的内存区域,Min和Max的数组访问时延非常稳定,其标准差非常小,而不使用mlock的内存区域,因为收到缺页异常和交换内存的影响,其最大延迟可以达到55170.11us,导致其标准差非常大。
总结
通过分析内核的实现,可以了解了mlock的基本原理,再通过一个测试程序,清楚的了解了mlock对实时程序的影响。
根据上述信息,可以发现使用mlock能够极大的提高程序的运行确定性,这对实时程序而言是非常有意义的。
处理mlock,通过madvise也能够辅助的提供程序的运行性能,这个有空分享一下。