我们知道任何机器运行都是依赖内存的,通常情况下我们不应该怀疑内存的硬件问题,但在RAS领域上不怀疑是不应该的,对于内存而言,其实很容易出现各类的问题,例如内存大面积损坏,内存单bit翻转等。本文不讨论内存的大面积破坏的问题,因为这已经是不可修复的大缺陷了。这里讨论一种情况,那就是内存的单bit翻转导致的数据不正确时在aarch64系列芯片上的硬件和软件措施
一、硬件纠错方案
1.1 Parity
Parity也就是奇偶校验,非常早期的单片机设备总线通信例如spi等,会用到这个,这个相信大家有过介绍和理解,这里重复一下。
奇偶校验就是在一组数据上,新增一个校验位,这个校验位用于计算1的个数,如果1的个数是奇数,则是1,如果偶数,则是0。
假设我们在传输数据时,某个bit发生了翻转现象,那么我们的校验位就能识别出来。
1.2 ECC
ECC也叫Error-Correcting Code memory,我们知道Parity在简单的数据通讯中能够提示部分错误,但是不能主动回复错误,那么ECC就是一种能够恢复位翻转错误的一种硬件技术,当代内存颗粒基本上都具备ECC校验的基本功能。 ECC有多种纠错算法。这里简单列举一下:
- SECDED(Single Error Correction Double Error Detection)
- SSCDSD(Single symbol correction double symbol detection)
- CRC(Cyclic Redundancy Check)
- Chipkill
二、软件实施方案
当我们了解了对于内存领域常见的硬件纠错方案之后,我们也需要知道软件是如何处理和规范解决这种ECC错误的
软件的方案在arm架构上主要有两点:
- ESB: Error Synchronization Barrier
- SDEI: Software Delegated Exception Interface
2.1 ESB
在arm中,对于内存的这类错误有一个单独的概念叫做ESB,他能够记录内存的同步错误。
2.1.1 ESB的描述
arm规范中,ESB如下描述:
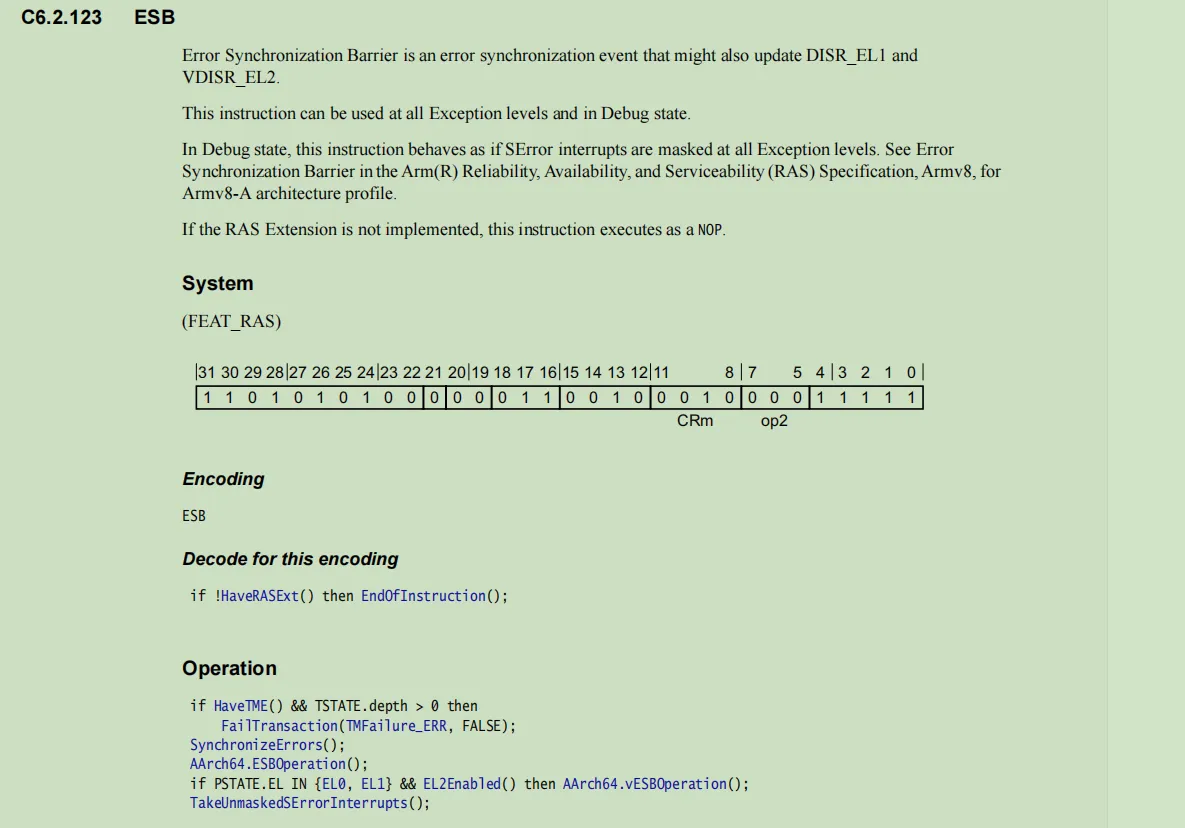 可以理解到,ESB是arm规范中作为错误同步屏障记录在特殊寄存器DISR(Deferred Interrupt Status Register)上并通过EL1层和EL2层上才能获取。
可以理解到,ESB是arm规范中作为错误同步屏障记录在特殊寄存器DISR(Deferred Interrupt Status Register)上并通过EL1层和EL2层上才能获取。
ESB的状态需要架构打开RAS扩展,否则作为空指令执行。
2.1.2 代码简析
对于ECC/Parity错误,在arm中默认是通过mm的fault来接受的,流程如下:
首先我们注意异常向量表如下:
SYM_CODE_START(vectors) kernel_ventry 1, sync_invalid // Synchronous EL1t kernel_ventry 1, irq_invalid // IRQ EL1t kernel_ventry 1, fiq_invalid // FIQ EL1t kernel_ventry 1, error_invalid // Error EL1t kernel_ventry 1, sync // Synchronous EL1h kernel_ventry 1, irq // IRQ EL1h kernel_ventry 1, fiq_invalid // FIQ EL1h kernel_ventry 1, error // Error EL1h kernel_ventry 0, sync // Synchronous 64-bit EL0 kernel_ventry 0, irq // IRQ 64-bit EL0 kernel_ventry 0, fiq_invalid // FIQ 64-bit EL0 kernel_ventry 0, error // Error 64-bit EL0 #ifdef CONFIG_COMPAT kernel_ventry 0, sync_compat, 32 // Synchronous 32-bit EL0 kernel_ventry 0, irq_compat, 32 // IRQ 32-bit EL0 kernel_ventry 0, fiq_invalid_compat, 32 // FIQ 32-bit EL0 kernel_ventry 0, error_compat, 32 // Error 32-bit EL0 #else kernel_ventry 0, sync_invalid, 32 // Synchronous 32-bit EL0 kernel_ventry 0, irq_invalid, 32 // IRQ 32-bit EL0 kernel_ventry 0, fiq_invalid, 32 // FIQ 32-bit EL0 kernel_ventry 0, error_invalid, 32 // Error 32-bit EL0 #endif SYM_CODE_END(vectors)
我们这里以el0的sync异常为例,因为内存的同步异常通过sync来触发,如下:
kernel_ventry 0, sync // Synchronous 64-bit EL0
此时对于的函数如下:
SYM_CODE_START_LOCAL_NOALIGN(el0_sync) kernel_entry 0 mov x0, sp bl el0_sync_handler b ret_to_user SYM_CODE_END(el0_sync)
这里发现会跳转到函数el0_sync_handler,其实现如下:
asmlinkage void noinstr el0_sync_handler(struct pt_regs *regs) { unsigned long esr = read_sysreg(esr_el1); switch (ESR_ELx_EC(esr)) { case ESR_ELx_EC_SVC64: el0_svc(regs); break; case ESR_ELx_EC_DABT_LOW: el0_da(regs, esr); break; case ESR_ELx_EC_IABT_LOW: el0_ia(regs, esr); break; case ESR_ELx_EC_FP_ASIMD: el0_fpsimd_acc(regs, esr); break; case ESR_ELx_EC_SVE: el0_sve_acc(regs, esr); break; case ESR_ELx_EC_FP_EXC64: el0_fpsimd_exc(regs, esr); break; case ESR_ELx_EC_SYS64: case ESR_ELx_EC_WFx: el0_sys(regs, esr); break; case ESR_ELx_EC_SP_ALIGN: el0_sp(regs, esr); break; case ESR_ELx_EC_PC_ALIGN: el0_pc(regs, esr); break; case ESR_ELx_EC_UNKNOWN: el0_undef(regs); break; case ESR_ELx_EC_BTI: el0_bti(regs); break; case ESR_ELx_EC_BREAKPT_LOW: case ESR_ELx_EC_SOFTSTP_LOW: case ESR_ELx_EC_WATCHPT_LOW: case ESR_ELx_EC_BRK64: el0_dbg(regs, esr); break; case ESR_ELx_EC_FPAC: el0_fpac(regs, esr); break; default: el0_inv(regs, esr); } }
我们留意data abort error,所以关心如下:
case ESR_ELx_EC_DABT_LOW: el0_da(regs, esr); break;
其函数如下
static void noinstr el0_da(struct pt_regs *regs, unsigned long esr) { unsigned long far = read_sysreg(far_el1); enter_from_user_mode(); local_daif_restore(DAIF_PROCCTX); do_mem_abort(far, esr, regs); }
我们看看跳转函数do_mem_abort的实现
void do_mem_abort(unsigned long far, unsigned int esr, struct pt_regs *regs) { const struct fault_info *inf = esr_to_fault_info(esr); unsigned long addr = untagged_addr(far); if (!inf->fn(far, esr, regs)) return; if (!user_mode(regs)) { pr_alert("Unhandled fault at 0x%016lx\n", addr); trace_android_rvh_do_mem_abort(regs, esr, addr, inf->name); mem_abort_decode(esr); show_pte(addr); } /* * At this point we have an unrecognized fault type whose tag bits may * have been defined as UNKNOWN. Therefore we only expose the untagged * address to the signal handler. */ arm64_notify_die(inf->name, regs, inf->sig, inf->code, addr, esr); }
这里留意函数esr_to_fault_info,如下:
static inline const struct fault_info *esr_to_fault_info(unsigned int esr) { return fault_info + (esr & ESR_ELx_FSC); }
所以我们应该关注这个核心的数组fault_info,如下:
static const struct fault_info fault_info[] = { { do_bad, SIGKILL, SI_KERNEL, "ttbr address size fault" }, { do_bad, SIGKILL, SI_KERNEL, "level 1 address size fault" }, { do_bad, SIGKILL, SI_KERNEL, "level 2 address size fault" }, { do_bad, SIGKILL, SI_KERNEL, "level 3 address size fault" }, { do_translation_fault, SIGSEGV, SEGV_MAPERR, "level 0 translation fault" }, { do_translation_fault, SIGSEGV, SEGV_MAPERR, "level 1 translation fault" }, { do_translation_fault, SIGSEGV, SEGV_MAPERR, "level 2 translation fault" }, { do_translation_fault, SIGSEGV, SEGV_MAPERR, "level 3 translation fault" }, { do_bad, SIGKILL, SI_KERNEL, "unknown 8" }, { do_page_fault, SIGSEGV, SEGV_ACCERR, "level 1 access flag fault" }, { do_page_fault, SIGSEGV, SEGV_ACCERR, "level 2 access flag fault" }, { do_page_fault, SIGSEGV, SEGV_ACCERR, "level 3 access flag fault" }, { do_bad, SIGKILL, SI_KERNEL, "unknown 12" }, { do_page_fault, SIGSEGV, SEGV_ACCERR, "level 1 permission fault" }, { do_page_fault, SIGSEGV, SEGV_ACCERR, "level 2 permission fault" }, { do_page_fault, SIGSEGV, SEGV_ACCERR, "level 3 permission fault" }, { do_sea, SIGBUS, BUS_OBJERR, "synchronous external abort" }, { do_tag_check_fault, SIGSEGV, SEGV_MTESERR, "synchronous tag check fault" }, { do_bad, SIGKILL, SI_KERNEL, "unknown 18" }, { do_bad, SIGKILL, SI_KERNEL, "unknown 19" }, { do_sea, SIGKILL, SI_KERNEL, "level 0 (translation table walk)" }, { do_sea, SIGKILL, SI_KERNEL, "level 1 (translation table walk)" }, { do_sea, SIGKILL, SI_KERNEL, "level 2 (translation table walk)" }, { do_sea, SIGKILL, SI_KERNEL, "level 3 (translation table walk)" }, { do_sea, SIGBUS, BUS_OBJERR, "synchronous parity or ECC error" }, // Reserved when RAS is implemented { do_bad, SIGKILL, SI_KERNEL, "unknown 25" }, { do_bad, SIGKILL, SI_KERNEL, "unknown 26" }, { do_bad, SIGKILL, SI_KERNEL, "unknown 27" }, { do_sea, SIGKILL, SI_KERNEL, "level 0 synchronous parity error (translation table walk)" }, // Reserved when RAS is implemented { do_sea, SIGKILL, SI_KERNEL, "level 1 synchronous parity error (translation table walk)" }, // Reserved when RAS is implemented { do_sea, SIGKILL, SI_KERNEL, "level 2 synchronous parity error (translation table walk)" }, // Reserved when RAS is implemented { do_sea, SIGKILL, SI_KERNEL, "level 3 synchronous parity error (translation table walk)" }, // Reserved when RAS is implemented { do_bad, SIGKILL, SI_KERNEL, "unknown 32" }, { do_alignment_fault, SIGBUS, BUS_ADRALN, "alignment fault" }, { do_bad, SIGKILL, SI_KERNEL, "unknown 34" }, { do_bad, SIGKILL, SI_KERNEL, "unknown 35" }, { do_bad, SIGKILL, SI_KERNEL, "unknown 36" }, { do_bad, SIGKILL, SI_KERNEL, "unknown 37" }, { do_bad, SIGKILL, SI_KERNEL, "unknown 38" }, { do_bad, SIGKILL, SI_KERNEL, "unknown 39" }, { do_bad, SIGKILL, SI_KERNEL, "unknown 40" }, { do_bad, SIGKILL, SI_KERNEL, "unknown 41" }, { do_bad, SIGKILL, SI_KERNEL, "unknown 42" }, { do_bad, SIGKILL, SI_KERNEL, "unknown 43" }, { do_bad, SIGKILL, SI_KERNEL, "unknown 44" }, { do_bad, SIGKILL, SI_KERNEL, "unknown 45" }, { do_bad, SIGKILL, SI_KERNEL, "unknown 46" }, { do_bad, SIGKILL, SI_KERNEL, "unknown 47" }, { do_bad, SIGKILL, SI_KERNEL, "TLB conflict abort" }, { do_bad, SIGKILL, SI_KERNEL, "Unsupported atomic hardware update fault" }, { do_bad, SIGKILL, SI_KERNEL, "unknown 50" }, { do_bad, SIGKILL, SI_KERNEL, "unknown 51" }, { do_bad, SIGKILL, SI_KERNEL, "implementation fault (lockdown abort)" }, { do_bad, SIGBUS, BUS_OBJERR, "implementation fault (unsupported exclusive)" }, { do_bad, SIGKILL, SI_KERNEL, "unknown 54" }, { do_bad, SIGKILL, SI_KERNEL, "unknown 55" }, { do_bad, SIGKILL, SI_KERNEL, "unknown 56" }, { do_bad, SIGKILL, SI_KERNEL, "unknown 57" }, { do_bad, SIGKILL, SI_KERNEL, "unknown 58" }, { do_bad, SIGKILL, SI_KERNEL, "unknown 59" }, { do_bad, SIGKILL, SI_KERNEL, "unknown 60" }, { do_bad, SIGKILL, SI_KERNEL, "section domain fault" }, { do_bad, SIGKILL, SI_KERNEL, "page domain fault" }, { do_bad, SIGKILL, SI_KERNEL, "unknown 63" }, };
这里我们留意ECC和Parity错误,如下:
{ do_sea, SIGBUS, BUS_OBJERR, "synchronous parity or ECC error" }, // Reserved when RAS is implemented
到这里,我们知道了常见的ECC/Parity错误会触发到软件的do_sea,这里我们重点开始关心软件上接受错误了是如何的行为,所以留意arm64_notify_die函数
void arm64_notify_die(const char *str, struct pt_regs *regs, int signo, int sicode, unsigned long far, int err) { if (user_mode(regs)) { WARN_ON(regs != current_pt_regs()); current->thread.fault_address = 0; current->thread.fault_code = err; arm64_force_sig_fault(signo, sicode, far, str); } else { die(str, regs, err); } }
这里可以看到区分了用户空间和内核空间
用户空间调用的是arm64_force_sig_fault,这里可以发现其发送了SIGBUS的错误
void arm64_force_sig_fault(int signo, int code, unsigned long far, const char *str) { arm64_show_signal(signo, str); if (signo == SIGKILL) force_sig(SIGKILL); else force_sig_fault(signo, code, (void __user *)far); }
force_sig_fault已经到信号的实现核心函数上了,这里不做解析了。
而内核空间则调用了die,这里直接oops了,如果打开了panic,则panic了。
void die(const char *str, struct pt_regs *regs, int err) { oops_exit(); if (in_interrupt()) panic("%s: Fatal exception in interrupt", str); if (panic_on_oops) panic("%s: Fatal exception", str); }
至此,我们可以发现,如果系统发生了ECC错误,那么会通过同步异常给到aarch64芯片,我们以el0为例,该错误会通过异常向量表给到do_sea函数,此函数会根据ecc的内存错误发生地方判断是否在用户空间,如果是用户空间,则通过bus error终结程序,如果是内核空间,则发送oops。
2.2 SDEI
SDEI是arm架构提出来的一套软件处理接口,我们从全称就可以了解Software Delegated Exception interface。它的逻辑是通过在非安全事件注册回调,
2.2.1 SDEI的描述
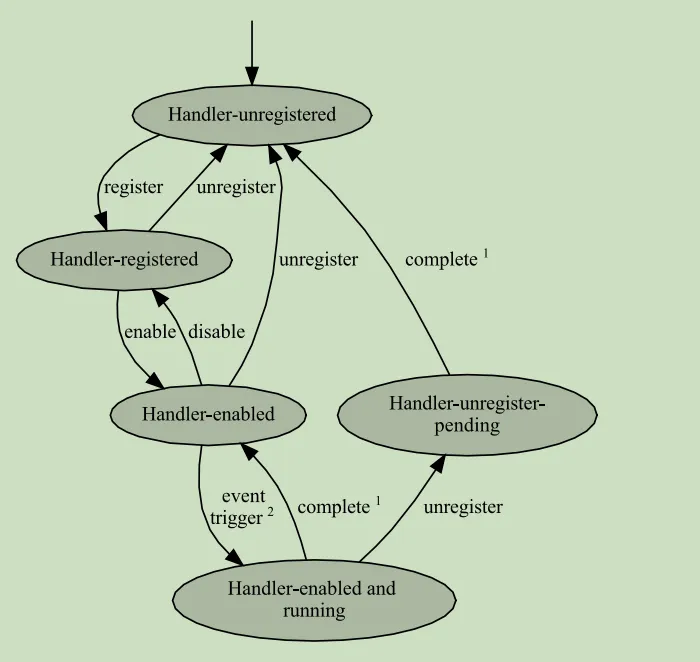
SDEI在spec中描述的实现在安全世界。其流程如下:
 SDEI会定义一系列的交互方式,如下:
SDEI会定义一系列的交互方式,如下:
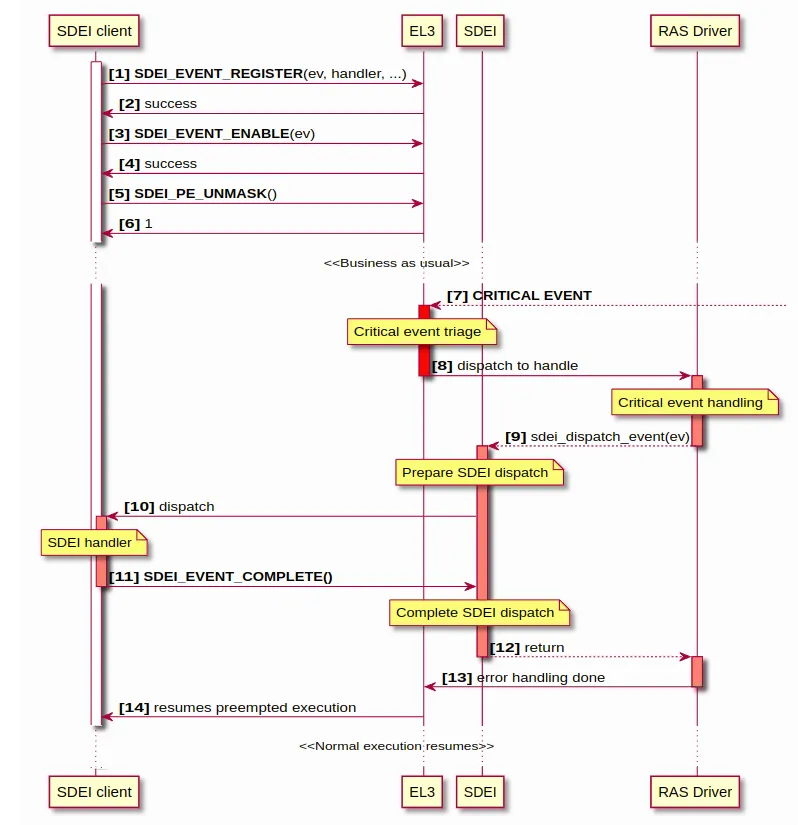 这里描述了SDEI handler的交互过程。
这里描述了SDEI handler的交互过程。
2.2.2 代码简析
我们关注trampoline如下:
SYM_CODE_START(__sdei_asm_entry_trampoline) mrs x4, ttbr1_el1 tbz x4, #USER_ASID_BIT, 1f tramp_map_kernel tmp=x4 isb mov x4, xzr /* * Use reg->interrupted_regs.addr_limit to remember whether to unmap * the kernel on exit. */ 1: str x4, [x1, #(SDEI_EVENT_INTREGS + S_ORIG_ADDR_LIMIT)] tramp_data_read_var x4, __sdei_asm_handler br x4 SYM_CODE_END(__sdei_asm_entry_trampoline)
其实现如下:
/* * Software Delegated Exception entry point. * * x0: Event number * x1: struct sdei_registered_event argument from registration time. * x2: interrupted PC * x3: interrupted PSTATE * x4: maybe clobbered by the trampoline * * Firmware has preserved x0->x17 for us, we must save/restore the rest to * follow SMC-CC. We save (or retrieve) all the registers as the handler may * want them. */ SYM_CODE_START(__sdei_asm_handler) stp x2, x3, [x1, #SDEI_EVENT_INTREGS + S_PC] stp x4, x5, [x1, #SDEI_EVENT_INTREGS + 16 * 2] stp x6, x7, [x1, #SDEI_EVENT_INTREGS + 16 * 3] stp x8, x9, [x1, #SDEI_EVENT_INTREGS + 16 * 4] stp x10, x11, [x1, #SDEI_EVENT_INTREGS + 16 * 5] stp x12, x13, [x1, #SDEI_EVENT_INTREGS + 16 * 6] stp x14, x15, [x1, #SDEI_EVENT_INTREGS + 16 * 7] stp x16, x17, [x1, #SDEI_EVENT_INTREGS + 16 * 8] stp x18, x19, [x1, #SDEI_EVENT_INTREGS + 16 * 9] stp x20, x21, [x1, #SDEI_EVENT_INTREGS + 16 * 10] stp x22, x23, [x1, #SDEI_EVENT_INTREGS + 16 * 11] stp x24, x25, [x1, #SDEI_EVENT_INTREGS + 16 * 12] stp x26, x27, [x1, #SDEI_EVENT_INTREGS + 16 * 13] stp x28, x29, [x1, #SDEI_EVENT_INTREGS + 16 * 14] mov x4, sp stp lr, x4, [x1, #SDEI_EVENT_INTREGS + S_LR] mov x19, x1 /* Store the registered-event for crash_smp_send_stop() */ ldrb w4, [x19, #SDEI_EVENT_PRIORITY] cbnz w4, 1f adr_this_cpu dst=x5, sym=sdei_active_normal_event, tmp=x6 b 2f 1: adr_this_cpu dst=x5, sym=sdei_active_critical_event, tmp=x6 2: str x19, [x5] #ifdef CONFIG_VMAP_STACK /* * entry.S may have been using sp as a scratch register, find whether * this is a normal or critical event and switch to the appropriate * stack for this CPU. */ cbnz w4, 1f ldr_this_cpu dst=x5, sym=sdei_stack_normal_ptr, tmp=x6 b 2f 1: ldr_this_cpu dst=x5, sym=sdei_stack_critical_ptr, tmp=x6 2: mov x6, #SDEI_STACK_SIZE add x5, x5, x6 mov sp, x5 #endif #ifdef CONFIG_SHADOW_CALL_STACK /* Use a separate shadow call stack for normal and critical events */ cbnz w4, 3f ldr_this_cpu dst=scs_sp, sym=sdei_shadow_call_stack_normal_ptr, tmp=x6 b 4f 3: ldr_this_cpu dst=scs_sp, sym=sdei_shadow_call_stack_critical_ptr, tmp=x6 4: #endif /* * We may have interrupted userspace, or a guest, or exit-from or * return-to either of these. We can't trust sp_el0, restore it. */ mrs x28, sp_el0 ldr_this_cpu dst=x0, sym=__entry_task, tmp=x1 msr sp_el0, x0 /* If we interrupted the kernel point to the previous stack/frame. */ and x0, x3, #0xc mrs x1, CurrentEL cmp x0, x1 csel x29, x29, xzr, eq // fp, or zero csel x4, x2, xzr, eq // elr, or zero stp x29, x4, [sp, #-16]! mov x29, sp add x0, x19, #SDEI_EVENT_INTREGS mov x1, x19 bl __sdei_handler msr sp_el0, x28 /* restore regs >x17 that we clobbered */ mov x4, x19 // keep x4 for __sdei_asm_exit_trampoline ldp x28, x29, [x4, #SDEI_EVENT_INTREGS + 16 * 14] ldp x18, x19, [x4, #SDEI_EVENT_INTREGS + 16 * 9] ldp lr, x1, [x4, #SDEI_EVENT_INTREGS + S_LR] mov sp, x1 mov x1, x0 // address to complete_and_resume /* x0 = (x0 <= 1) ? EVENT_COMPLETE:EVENT_COMPLETE_AND_RESUME */ cmp x0, #1 mov_q x2, SDEI_1_0_FN_SDEI_EVENT_COMPLETE mov_q x3, SDEI_1_0_FN_SDEI_EVENT_COMPLETE_AND_RESUME csel x0, x2, x3, ls ldr_l x2, sdei_exit_mode /* Clear the registered-event seen by crash_smp_send_stop() */ ldrb w3, [x4, #SDEI_EVENT_PRIORITY] cbnz w3, 1f adr_this_cpu dst=x5, sym=sdei_active_normal_event, tmp=x6 b 2f 1: adr_this_cpu dst=x5, sym=sdei_active_critical_event, tmp=x6 2: str xzr, [x5] alternative_if_not ARM64_UNMAP_KERNEL_AT_EL0 sdei_handler_exit exit_mode=x2 alternative_else_nop_endif #ifdef CONFIG_UNMAP_KERNEL_AT_EL0 tramp_alias dst=x5, sym=__sdei_asm_exit_trampoline, tmp=x3 br x5 #endif SYM_CODE_END(__sdei_asm_handler) NOKPROBE(__sdei_asm_handler)
这里我们关注其跳转如下:
bl __sdei_handler
其实现如下:
asmlinkage noinstr unsigned long __sdei_handler(struct pt_regs *regs, struct sdei_registered_event *arg) { unsigned long ret; arm64_enter_nmi(regs); ret = _sdei_handler(regs, arg); arm64_exit_nmi(regs); return ret; }
对于_sdei_handler,会按照SDEI协议的event handler去处理,其函数如下:
static __kprobes unsigned long _sdei_handler(struct pt_regs *regs, struct sdei_registered_event *arg) { u32 mode; int i, err = 0; int clobbered_registers = 4; u64 elr = read_sysreg(elr_el1); u32 kernel_mode = read_sysreg(CurrentEL) | 1; /* +SPSel */ unsigned long vbar = read_sysreg(vbar_el1); if (arm64_kernel_unmapped_at_el0()) clobbered_registers++; /* Retrieve the missing registers values */ for (i = 0; i < clobbered_registers; i++) { /* from within the handler, this call always succeeds */ sdei_api_event_context(i, ®s->regs[i]); } /* * We didn't take an exception to get here, set PAN. UAO will be cleared * by sdei_event_handler()s force_uaccess_begin() call. */ __uaccess_enable_hw_pan(); err = sdei_event_handler(regs, arg); if (err) return SDEI_EV_FAILED; if (elr != read_sysreg(elr_el1)) { /* * We took a synchronous exception from the SDEI handler. * This could deadlock, and if you interrupt KVM it will * hyp-panic instead. */ pr_warn("unsafe: exception during handler\n"); } mode = regs->pstate & (PSR_MODE32_BIT | PSR_MODE_MASK); /* * If we interrupted the kernel with interrupts masked, we always go * back to wherever we came from. */ if (mode == kernel_mode && !interrupts_enabled(regs)) return SDEI_EV_HANDLED; /* * Otherwise, we pretend this was an IRQ. This lets user space tasks * receive signals before we return to them, and KVM to invoke it's * world switch to do the same. * * See DDI0487B.a Table D1-7 'Vector offsets from vector table base * address'. */ if (mode == kernel_mode) return vbar + 0x280; else if (mode & PSR_MODE32_BIT) return vbar + 0x680; return vbar + 0x480; }
这里我们关注函数sdei_event_handler,此时函数是acpi/fdt实现的firmware驱动,如下
int sdei_event_handler(struct pt_regs *regs, struct sdei_registered_event *arg) { int err; mm_segment_t orig_addr_limit; u32 event_num = arg->event_num; /* * Save restore 'fs'. * The architecture's entry code save/restores 'fs' when taking an * exception from the kernel. This ensures addr_limit isn't inherited * if you interrupted something that allowed the uaccess routines to * access kernel memory. * Do the same here because this doesn't come via the same entry code. */ orig_addr_limit = force_uaccess_begin(); err = arg->callback(event_num, regs, arg->callback_arg); if (err) pr_err_ratelimited("event %u on CPU %u failed with error: %d\n", event_num, smp_processor_id(), err); force_uaccess_end(orig_addr_limit); return err; } NOKPROBE_SYMBOL(sdei_event_handler);
接下来的流程,就完全符合SDEI定义的交互流程了。
三、rasdaemon
回顾了这些代码,在学习sdei的时候,意外发现一个仓库rasdaemon,此仓库是目的是通过一个上层的程序,捕获常见的ras领域的错误,当然也包括我们的内存单bit翻转的错误。
对于rasdaemon,可以将内存的错误数量进行统计。提供给用户查看。
不幸的是,此工具不在aarch64上实现,我们但是我们在amd上可以看到如下实现:
parse_amd_smca_event--->decode_smca_error
我们随便以smca_mce_descs中的一种desc描述示例如下:
static const char * const smca_smu2_mce_desc[] = { "High SRAM ECC or parity error", "Low SRAM ECC or parity error", "Data Cache Bank A ECC or parity error", "Data Cache Bank B ECC or parity error", "Data Tag Cache Bank A ECC or parity error", "Data Tag Cache Bank B ECC or parity error", "Instruction Cache Bank A ECC or parity error", "Instruction Cache Bank B ECC or parity error", "Instruction Tag Cache Bank A ECC or parity error", "Instruction Tag Cache Bank B ECC or parity error", "System Hub Read Buffer ECC or parity error", "PHY RAS ECC Error", [12 ... 57] = "Reserved", "A correctable error from a GFX Sub-IP", "A fatal error from a GFX Sub-IP", "Reserved", "Reserved", "A poison error from a GFX Sub-IP", "Reserved", };
可以发现,其desc能够捕获ECC和Parity error。
但是鉴于自己没有对应的机器实践,rasdaemon并没有尝试验证。
四、参考文档:
- memoryerrors-asplos15.pdf

- ARM_DDI_0587C_a_RAS.pdf

- ARM_DEN0054C_Software_Delegated_Exception_Interface.pdf

项目中遇到客户的USB接U盘,如果是3.0系统会直接在内核卡死,卡死在经典函数blk_update_request上,我们知道,这肯定是因为同步导致的,因为io同步需要通过usb controler来执行真正的io,落盘到usb的usbstorage上,问题很简单,usb 控制器驱动那边有问题,来源是硬件。
但是同事有提问,如果是同步原语,那么是自旋锁还是互斥锁还是其他呢?我一时没有给出正确答案,另一个问题,这个问题是解决了,那我到底能了解什么呢,能了解USB吗,其实不能,能了解文件系统吗,其实也不能,我私以为能了解的就只有同步原语,或者直接点,了解锁。这里为了了解锁,介绍一下ABBA锁场景死锁。
本文以原来项目问题为起始,做了锁的ABBA衍生,一方面解答了自旋锁和其他锁的表象问题,一方面简单介绍了经典abba锁问题,供大家知悉,仅此而已。
一、简单介绍几个同步原语
主要的同步原语这里有四类,具体介绍这里就不说明了,很多书都会详细介绍
自旋锁:竞争时自旋等待,临界区无法休眠
互斥锁:竞争时可睡眠,
信号量:同互斥锁
完成量:等待完成
根据这四种,有不同的变体,除了完成量,其他都能在不严谨的编程中造成abba锁。故咱们仅谈谈上述三种的基本锁,不谈其他变体,例如顺序锁,读写锁,读写信号,多值信号等等。
1.1 ABBA锁
什么是ABBA锁呢,如下图示:
 两个线程中,thread1拿锁A,此时尝试锁B,然后thread2拿锁B,此时尝试锁A,此时thread1和thread2都拿不到B锁和A锁,在这种状态下,互相锁死,也就是场景的ABBA锁的模型。
两个线程中,thread1拿锁A,此时尝试锁B,然后thread2拿锁B,此时尝试锁A,此时thread1和thread2都拿不到B锁和A锁,在这种状态下,互相锁死,也就是场景的ABBA锁的模型。
代码示例
介绍ABBA锁非常简单,但是代码中ABBA的场景却非常复杂,这里先以最简单的驱动来示例这个ABBA的问题,总代码如下:
#include <linux/init.h> #include <linux/mutex.h> #include <linux/module.h> #include <linux/spinlock.h> #include <linux/kthread.h> #include <linux/delay.h> static DEFINE_SPINLOCK(spinlock_a); static DEFINE_SPINLOCK(spinlock_b); static DEFINE_MUTEX(mutex_a); static DEFINE_MUTEX(mutex_b); static DEFINE_SEMAPHORE(semaphore_a); static DEFINE_SEMAPHORE(semaphore_b); static int testsuite = 0; module_param(testsuite, int, S_IWUSR | S_IRUSR | S_IWGRP | S_IRGRP); MODULE_PARM_DESC(testsuite, "Test Lock Suilte"); static struct task_struct *thread1, *thread2; static int thread_1(void *arg) { char *name = (char*)arg; pr_info("Thread %s starting...\n", name); while(!kthread_should_stop()){ schedule_timeout(msecs_to_jiffies(1000)); if(testsuite == 0x1){ spin_lock(&spinlock_a); pr_info("Thread %s hold spinlock_a trying spinlock_b \n", name); spin_lock(&spinlock_b); pr_info("%s:Do something...\n", name); spin_unlock(&spinlock_b); spin_unlock(&spinlock_a); pr_info("Thread %s unlock\n", name); } if(testsuite == 0x2){ mutex_lock(&mutex_a); pr_info("Thread %s hold mutex_a trying mutex_b\n", name); mutex_lock(&mutex_b); pr_info("%s:Do something...\n", name); mutex_unlock(&mutex_b); mutex_unlock(&mutex_a); } if(testsuite == 0x3){ down(&semaphore_a); pr_info("Thread %s hold semaphore_a trying semaphore_b\n", name); down(&semaphore_b); pr_info("%s:Do something...\n", name); up(&semaphore_b); up(&semaphore_a); } } return 0; } static int thread_2(void *arg) { char *name = (char*)arg; pr_info("Thread %s starting...\n", name); while(!kthread_should_stop()){ schedule_timeout(msecs_to_jiffies(1000)); if(testsuite == 0x1){ spin_lock(&spinlock_b); pr_info("Thread %s hold spinlock_b trying spinlock_a \n", name); spin_lock(&spinlock_a); pr_info("%s:Do something...\n", name); spin_unlock(&spinlock_a); spin_unlock(&spinlock_b); pr_info("Thread %s unlock\n", name); } if(testsuite == 0x2){ mutex_lock(&mutex_b); pr_info("Thread %s hold mutex_b trying mutex_a\n", name); mutex_lock(&mutex_a); pr_info("%s:Do something...\n", name); mutex_unlock(&mutex_a); mutex_unlock(&mutex_b); } if(testsuite == 0x3){ down(&semaphore_b); pr_info("Thread %s hold semaphore_b trying semaphore_a\n", name); down(&semaphore_a); pr_info("%s:Do something...\n", name); up(&semaphore_a); up(&semaphore_b); } } return 0; } static void start_test(void) { thread1 = kthread_run(thread_1, "Thread-1", "spinlock_thread1"); thread2 = kthread_run(thread_2, "Thread-2", "spinlock_thread2"); return ; } static int __init test_init(void) { start_test(); return 0; } static void __exit test_exit(void) { kthread_stop(thread1); kthread_stop(thread2); return; } module_init(test_init); module_exit(test_exit); MODULE_AUTHOR("tangfeng <tangfeng@kylinos.cn>"); MODULE_DESCRIPTION("Test spinlock/mutex/semaphore"); MODULE_LICENSE("GPL");
2.1 Spinlock版本ABBA
为了支持自旋版本的ABBA,两个线程分别如下:
对于thread1:
spin_lock(&spinlock_a); pr_info("Thread %s hold spinlock_a trying spinlock_b \n", name); spin_lock(&spinlock_b); pr_info("%s:Do something...\n", name); spin_unlock(&spinlock_b); spin_unlock(&spinlock_a); pr_info("Thread %s unlock\n", name);
对于thread2:
spin_lock(&spinlock_b); pr_info("Thread %s hold spinlock_b trying spinlock_a \n", name); spin_lock(&spinlock_a); pr_info("%s:Do something...\n", name); spin_unlock(&spinlock_a); spin_unlock(&spinlock_b); pr_info("Thread %s unlock\n", name);
此时我们加载运行,日志如下:
[ 247.149092] test: module is from the staging directory, the quality is unknown, you have been warned. [ 247.150668] Thread Thread-1 starting... [ 247.150736] Thread Thread-1 hold spinlock_a trying spinlock_b [ 247.150740] Thread-1:Do something... [ 247.150744] Thread Thread-1 unlock [ 247.150748] Thread Thread-2 starting... [ 247.150753] Thread Thread-2 hold spinlock_b trying spinlock_a [ 247.150755] Thread Thread-1 hold spinlock_a trying spinlock_b [ 307.143419] rcu: INFO: rcu_sched self-detected stall on CPU [ 307.143446] rcu: 0-....: (17996 ticks this GP) idle=6a2/1/0x4000000000000002 softirq=4790/4790 fqs=5944 last_accelerate: 0000/04c6 dyntick_enabled: 0 [ 307.143453] (t=18000 jiffies g=14105 q=7019) [ 307.143458] Task dump for CPU 0: [ 307.143464] task:spinlock_thread state:R running task stack: 0 pid: 7795 ppid: 2 flags:0x0000000a [ 307.143474] Call trace: [ 307.143484] dump_backtrace+0x0/0x1e8 [ 307.143491] show_stack+0x1c/0x28 [ 307.143498] sched_show_task+0x154/0x178 [ 307.143505] dump_cpu_task+0x48/0x54 [ 307.143511] rcu_dump_cpu_stacks+0xbc/0xfc [ 307.143517] rcu_sched_clock_irq+0x8b0/0x9d8 [ 307.143524] update_process_times+0x64/0xa0 [ 307.143530] tick_sched_handle.isra.0+0x38/0x58 [ 307.143535] tick_sched_timer+0x50/0xa0 [ 307.143540] __hrtimer_run_queues+0x148/0x2d8 [ 307.143546] hrtimer_interrupt+0xec/0x240 [ 307.143553] arch_timer_handler_phys+0x38/0x48 [ 307.143559] handle_percpu_devid_irq+0x8c/0x210 [ 307.143565] __handle_domain_irq+0x78/0xd8 [ 307.143571] gic_handle_irq+0x88/0x2d8 [ 307.143576] el1_irq+0xc8/0x180 [ 307.143582] queued_spin_lock_slowpath+0x128/0x3b0 [ 307.143587] do_raw_spin_lock+0xd4/0x130 [ 307.143594] _raw_spin_lock+0x14/0x20 [ 307.143605] thread_1+0x174/0x248 [test] [ 307.143612] kthread+0x100/0x130 [ 307.143618] ret_from_fork+0x10/0x18 [ 307.143622] Task dump for CPU 3: [ 307.143626] task:spinlock_thread state:R running task stack: 0 pid: 7796 ppid: 2 flags:0x0000000a [ 307.143635] Call trace: [ 307.143640] __switch_to+0xe4/0x138 [ 307.143645] 0xffffffc00d77be00 [ 307.143651] kthread+0x100/0x130 [ 307.143656] ret_from_fork+0x10/0x18 [ 308.190088] rcu: INFO: rcu_sched detected expedited stalls on CPUs/tasks: { 0-... 3-... } 18312 jiffies s: 753 root: 0x9/. [ 308.190098] rcu: blocking rcu_node structures: [ 308.190101] Task dump for CPU 0: [ 308.190103] task:spinlock_thread state:R running task stack: 0 pid: 7795 ppid: 2 flags:0x0000000a [ 308.190107] Call trace: [ 308.190112] __switch_to+0xe4/0x138 [ 308.190115] 0xffffffc00d73be00 [ 308.190118] kthread+0x100/0x130 [ 308.190121] ret_from_fork+0x10/0x18 [ 308.190123] Task dump for CPU 3: [ 308.190124] task:spinlock_thread state:R running task stack: 0 pid: 7796 ppid: 2 flags:0x0000000a [ 308.190128] Call trace: [ 308.190130] __switch_to+0xe4/0x138 [ 308.190132] 0xffffffc00d77be00 [ 308.190134] kthread+0x100/0x130 [ 308.190137] ret_from_fork+0x10/0x18
我们可以通过日志发现:
[ 247.150753] Thread Thread-2 hold spinlock_b trying spinlock_a [ 247.150755] Thread Thread-1 hold spinlock_a trying spinlock_b
thread2先锁住了spinlock_b,然后尝试spinlock_a,而同时thread1锁住了spinlock_a,然后尝试spinlock_b,这就是典型的baab状态。
我们可以留意到如下:
zcat /proc/config.gz | grep CONFIG_RCU_CPU_STALL_TIMEOUT CONFIG_RCU_CPU_STALL_TIMEOUT=60
可以发现rcu stall检测器正好能够检测到spinlock的abba死锁问题
2.2 mutex版本ABBA
mutex版本的两个thread的代码如下:
thread1:
mutex_lock(&mutex_a); pr_info("Thread %s hold mutex_a trying mutex_b\n", name); mutex_lock(&mutex_b); pr_info("%s:Do something...\n", name); mutex_unlock(&mutex_b); mutex_unlock(&mutex_a);
thread2:
mutex_lock(&mutex_b); pr_info("Thread %s hold mutex_b trying mutex_a\n", name); mutex_lock(&mutex_a); pr_info("%s:Do something...\n", name); mutex_unlock(&mutex_a); mutex_unlock(&mutex_b);
此时我们加载运行,日志如下:
[ 111.601145] Thread Thread-1 starting... [ 111.601222] Thread Thread-1 hold mutex_a trying mutex_b [ 111.601226] Thread-1:Do something... [ 111.601230] Thread Thread-1 hold mutex_a trying mutex_b [ 111.601234] Thread-1:Do something... [ 111.601239] Thread Thread-1 hold mutex_a trying mutex_b [ 111.601244] Thread Thread-2 starting... [ 111.601248] Thread Thread-2 hold mutex_b trying mutex_a
thread1先锁住了mutex_a,然后尝试mutex_b,而同时thread2启动,锁住了mutex_b,然后尝试mutex_a,完成了abba死锁状态。
但是可以发现,此时我们rct stall并不会检测死锁原因,因为mutex在竞争不过的时候会休眠,操作系统仍可以正常使用。为了能够检测这种可休眠的锁的竞争问题,我们需要打开hungtask配置,由内核启动khungtaskd来用于检测软锁问题,如下:
CONFIG_DETECT_HUNG_TASK=y CONFIG_DEFAULT_HUNG_TASK_TIMEOUT=120
当我们的内核支持hungtask后,可以发现内核默认线程khungtaskd启动,如下:
root@kylin:~# ps -ax | grep hungtaskd 71 ? S 0:00 [khungtaskd]
此时,mutex的abba锁存在堆栈,如下:
[ 248.461569] INFO: task spinlock_thread:4537 blocked for more than 122 seconds. [ 248.461598] Tainted: G C 5.10.198 #20 [ 248.461603] "echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message. [ 248.461609] task:spinlock_thread state:D stack: 0 pid: 4537 ppid: 2 flags:0x00000008 [ 248.461618] Call trace: [ 248.461629] __switch_to+0xe4/0x138 [ 248.461637] __schedule+0x2b4/0x818 [ 248.461643] schedule+0x4c/0xd0 [ 248.461649] schedule_preempt_disabled+0x14/0x20 [ 248.461655] __mutex_lock.isra.0+0x184/0x588 [ 248.461660] __mutex_lock_slowpath+0x18/0x20 [ 248.461665] mutex_lock+0x7c/0x88 [ 248.461676] thread_1+0x1f4/0x220 [test] [ 248.461682] kthread+0x100/0x130 [ 248.461688] ret_from_fork+0x10/0x18 [ 248.461693] INFO: task spinlock_thread:4538 blocked for more than 122 seconds. [ 248.461698] Tainted: G C 5.10.198 #20 [ 248.461702] "echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message. [ 248.461706] task:spinlock_thread state:D stack: 0 pid: 4538 ppid: 2 flags:0x00000008 [ 248.461712] Call trace: [ 248.461718] __switch_to+0xe4/0x138 [ 248.461723] __schedule+0x2b4/0x818 [ 248.461728] schedule+0x4c/0xd0 [ 248.461733] schedule_preempt_disabled+0x14/0x20 [ 248.461738] __mutex_lock.isra.0+0x184/0x588 [ 248.461744] __mutex_lock_slowpath+0x18/0x20 [ 248.461754] mutex_lock+0x7c/0x88 [ 248.461761] thread_2+0xec/0x180 [test] [ 248.461766] kthread+0x100/0x130 [ 248.461771] ret_from_fork+0x10/0x18
2.3 semaphore版本ABBA
semaphore版本的两个thread如下:
thread1:
down(&semaphore_a); pr_info("Thread %s hold semaphore_a trying semaphore_b\n", name); down(&semaphore_b); pr_info("%s:Do something...\n", name); up(&semaphore_b); up(&semaphore_a);
thread2:
down(&semaphore_b); pr_info("Thread %s hold semaphore_b trying semaphore_a\n", name); down(&semaphore_a); pr_info("%s:Do something...\n", name); up(&semaphore_a); up(&semaphore_b);
此时加载运行,日志如下:
[ 41.624824] Thread Thread-1 starting... [ 41.625040] Thread Thread-1 hold semaphore_a trying semaphore_b [ 41.625044] Thread-1:Do something... [ 41.625050] Thread Thread-2 starting... [ 41.625051] Thread Thread-1 hold semaphore_a trying semaphore_b [ 41.625055] Thread-1:Do something... [ 41.625076] Thread Thread-1 hold semaphore_a trying semaphore_b [ 41.625130] Thread Thread-2 hold semaphore_b trying semaphore_a [ 248.458566] INFO: task spinlock_thread:3817 blocked for more than 122 seconds. [ 248.458597] Tainted: G C 5.10.198 #20 [ 248.458602] "echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message. [ 248.458607] task:spinlock_thread state:D stack: 0 pid: 3817 ppid: 2 flags:0x00000008 [ 248.458616] Call trace: [ 248.458627] __switch_to+0xe4/0x138 [ 248.458635] __schedule+0x2b4/0x818 [ 248.458640] schedule+0x4c/0xd0 [ 248.458646] schedule_timeout+0x290/0x2f0 [ 248.458652] __down+0x74/0xd0 [ 248.458659] down+0x50/0x68 [ 248.458670] thread_1+0xb4/0x220 [test] [ 248.458677] kthread+0x100/0x130 [ 248.458683] ret_from_fork+0x10/0x18 [ 248.458688] INFO: task spinlock_thread:3818 blocked for more than 122 seconds. [ 248.458693] Tainted: G C 5.10.198 #20 [ 248.458696] "echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message. [ 248.458701] task:spinlock_thread state:D stack: 0 pid: 3818 ppid: 2 flags:0x00000008 [ 248.458707] Call trace: [ 248.458712] __switch_to+0xe4/0x138 [ 248.458718] __schedule+0x2b4/0x818 [ 248.458723] schedule+0x4c/0xd0 [ 248.458728] schedule_timeout+0x290/0x2f0 [ 248.458733] __down+0x74/0xd0 [ 248.458738] down+0x50/0x68 [ 248.458745] thread_2+0x140/0x180 [test] [ 248.458751] kthread+0x100/0x130 [ 248.458756] ret_from_fork+0x10/0x18
因为semaphore和mutex实现类似,故hungtask仍可以检测semaphore的abba问题
三、调试锁问题
上面可以查看锁的问题,为了调试锁,我们需要打开内核的LOCKDEP。主要配置如下:
CONFIG_LOCK_STAT=y CONFIG_PROVE_LOCKING=y CONFIG_DEBUG_LOCKDEP=y
此时我们的日志能够更清晰的查看abba锁的内容信息,举例如下:
[ 371.125970] ====================================================== [ 371.132162] [ INFO: possible circular locking dependency detected ] [ 371.138445] 4.9.88 #2 Tainted: G O [ 371.142987] ------------------------------------------------------- [ 371.149265] kworker/0:2/104 is trying to acquire lock: ..............................
为了可调试,可以直接如下:
cat /proc/lockdep
此时出现系统所有lock的地址
all lock classes: 0000000044beef8b ....: logbuf_lock 00000000c80448bf ....: (console_sem).lock 00000000700ad619 ....: console_lock 00000000ef505732 ....: cgroup_mutex 0000000042291e92 ....: console_owner_lock 000000002e29cf8c ....: console_owner .....................
也可以看lock的stat,如下
cat /proc/lockdep_stats lock-classes: 1851 [max: 8191] direct dependencies: 0 [max: 32768] indirect dependencies: 0 all direct dependencies: 0 in-hardirq chains: 0 ....................
之前说明了systemtap在ubuntu上安装和测试的基本方法,这个以具体的内核函数的观察来实践一把,主要完成ubuntu上观测鼠标移动和亮度设置函数调用。主要步骤如下
-
通过代码确定鼠标移动和亮度设置的内核代码函数
-
通过stap -L确定stap是否能够识别这些函数
-
编写stap脚本,在函数call的时候进行一些新的打印
-
运行stap脚本,在ubuntu上滑动鼠标和调节亮度触发观测点
一.确定代码
鼠标移动代码
drivers/gpu/drm/radeon/radeon_cursor.c radeon_crtc_cursor_move
亮度调节代码
drivers/gpu/drm/radeon/atombios_encoders.c atombios_set_backlight_level
二.确定这些函数是否stap识别
鼠标移动
# stap -L 'module("radeon").function("radeon_crtc_cursor_move")' module("radeon").function("radeon_crtc_cursor_move@drivers/gpu/drm/radeon/radeon_cursor.c:264") $crtc:struct drm_crtc* $x:int $y:int
亮度调节
# stap -L 'module("radeon").function("atombios_set_backlight_level")' module("radeon").function("atombios_set_backlight_level@drivers/gpu/drm/radeon/atombios_encoders.c:94") $radeon_encoder:struct radeon_encoder* $level:u8 $args:DISPLAY_DEVICE_OUTPUT_CONTROL_PARAMETERS
三.编写stap脚本
在确定了stap能够识别这个函数之后,可以写观测脚本如下
观测鼠标移动
probe module("radeon").function("radeon_crtc_cursor_move").call { printf("[func]%s :", probefunc()); printf("x=%d y=%d\n", $x, $y); print_backtrace(); }
这里打印了函数名称,函数的入参x和y,函数的堆栈
观测亮度调节
probe module("radeon").function("atombios_set_backlight_level").call { printf("[func]%s \n", probefunc()); printf("level=%d \n", $level); printf("encoder_id=%d \n", $radeon_encoder->encoder_id); print_backtrace(); }
四 运行stap脚本
stap -v test.stp
运行到pass 5时,可以开始进行测试了
这时候滑动鼠标和通过系统设置调节亮度时,stap这里会打印如下的日志
鼠标的
[func]radeon_crtc_cursor_move :x=779 y=428 0xffffffffc03daab0 : radeon_crtc_cursor_move+0x0/0x50 [radeon] 0xffffffffc01785d4 0xffffffffc01785d4 0xffffffffc01789da 0xffffffffc015d30e 0xffffffffc015d5a7 0xffffffffc03b204e : radeon_drm_ioctl+0x4e/0x80 [radeon] 0xffffffffa0135021 : __x64_sys_ioctl+0x91/0xc0 [kernel] 0xffffffffa09f2ed1 : do_syscall_64+0x61/0xb0 [kernel] 0xffffffffa0c0007c : entry_SYSCALL_64_after_hwframe+0x44/0xae [kernel]
亮度的
[func]atombios_set_backlight_level level=156 encoder_id=33 0xffffffffc042ba70 : atombios_set_backlight_level+0x0/0x180 [radeon] 0xffffffffc042bc20 : radeon_atom_backlight_update_status+0x30/0x40 [radeon] 0xffffffffa045206b : backlight_device_set_brightness+0x6b/0xd0 [kernel] 0xffffffffa0452131 : brightness_store+0x61/0x80 [kernel] 0xffffffffa058bc57 : dev_attr_store+0x17/0x30 [kernel] 0xffffffffa01e007e : sysfs_kf_write+0x3e/0x50 [kernel] 0xffffffffa01df188 : kernfs_fop_write_iter+0x138/0x1c0 [kernel] 0xffffffffa011b377 : new_sync_write+0x117/0x1b0 [kernel] 0xffffffffa011db55 : vfs_write+0x185/0x250 [kernel] 0xffffffffa011dda7 : ksys_write+0x67/0xe0 [kernel] 0xffffffffa011de3a : __x64_sys_write+0x1a/0x20 [kernel] 0xffffffffa09f2ed1 : do_syscall_64+0x61/0xb0 [kernel] 0xffffffffa0c0007c : entry_SYSCALL_64_after_hwframe+0x44/0xae [kernel] 0xffffffffa0c0007c : entry_SYSCALL_64_after_hwframe+0x44/0xae [kernel] 0xffffffffa0451b50 : brightness_show+0x0/0x30 [kernel] 0xffffffffa058c80d : dev_attr_show+0x1d/0x40 [kernel] 0xffffffffa01e0841 : sysfs_kf_seq_show+0xa1/0x100 [kernel] 0xffffffffa01de9e7 : kernfs_seq_show+0x27/0x30 [kernel] 0xffffffffa014ba00 : seq_read_iter+0x120/0x450 [kernel] 0xffffffffa01df4a0 : kernfs_fop_read_iter+0x150/0x1b0 [kernel] 0xffffffffa011b1d0 : new_sync_read+0x110/0x1a0 [kernel] 0xffffffffa011d93e : vfs_read+0xfe/0x190 [kernel] 0xffffffffa011dc87 : ksys_read+0x67/0xe0 [kernel] 0xffffffffa011dd1a : __x64_sys_read+0x1a/0x20 [kernel] 0xffffffffa09f2ed1 : do_syscall_64+0x61/0xb0 [kernel] 0xffffffffa0c0007c : entry_SYSCALL_64_after_hwframe+0x44/0xae [kernel] 0xffffffffa0c0007c : entry_SYSCALL_64_after_hwframe+0x44/0xae [kernel]
至此,就可以通过stap完成对内核函数的观测。只要stap能够识别到内核的函数,就能正常的观测。
这里再解释一下stap默认的函数意思
1.kernel.function("function") 这是指的内核的功能函数 2.module("module").function("function") 这是模块的功能函数 3.probe begin { printf ("hello world\n") } 在观测前打印 4.thread_indent() 返回时间戳+进程名+线程id 例如 1159 ftp(7223) 5.target() 如果stap使用 stap -x PID 这里可以用 if (pid() == target()) 来筛选观测的应用 6.$var 是表述一个变量 例如 printf("x=%d y=%d\n", $x, $y); 这个变量可以通过stap -L 查看到,然后根据实际情况去printf就行 print_backtrace() 打印内核堆栈回溯 ppfunc() 返回从中解析的函数名
如果想观测一个内核文件所有的函数是否被调用,可以
probe module("radeon").function("*@drivers/gpu/drm/radeon/radeon_cursor.c").call
这里格式应该是
function@path:line
如果取
*@path 也就是 *@drivers/gpu/drm/radeon/radeon_cursor.c
代表这个文件的所有函数都观测
参考链接
https://sourceware.org/systemtap/tutorial/tutorialli1.html
https://spacewander.gitbooks.io/systemtapbeginnersguide_zh/content/
https://sourceware.org/systemtap/tapsets/
https://sourceware.org/systemtap/examples/
https://sourceware.org/systemtap/SystemTap_Beginners_Guide/
https://sourceware.org/systemtap/langref/
https://sourceware.org/systemtap/man/index.html
当然,stap也可以观测用户程序,后续有时间再演示吧
主要步骤:
-
浏览器添加扩展tampermonkey
-
在tampermonkey里面搜索脚本并安装
-
进入bdwp网页版,然后点击简易下载助手(仅单个文件)
-
使用aria2下载
一:添加扩展
在浏览器设置--->扩展程序--->搜索扩展程序---->Tampermonkey---->安装
二:搜索脚本
地址栏最右边---->点击扩展图标---->获取新脚本--->点击GreasyFork
出现如下

搜索 "bdwp" 的中文 得到《bdwpjyxzzs(zlxzfhb)》
点进去,点击安装即可
三:点击下载
进入网页版,可以看到多了一个按键如下

然后下载单个文件,点击获取直链地址
四:使用aria2下载
vbs文件
CreateObject("WScript.Shell").Run "aria2c.exe --conf-path=config.conf",0
然后网页登录
http://aria2c.com
等等即可下载
在ldd上看到了systemtap这个东西,他是基于kprobe的内核调试工具,这里主要描述一下systemtap前期的环境搭建,和运行简单的systemtap命令
主要有如下几个步骤
-
拉取内核源码
-
配置内核config和编译
-
编译systemtap源码
-
使用stap命令进行简单的测试使用
一:内核源码
这里我使用的是ubuntu2004,可用直接通过apt命令拉取内核代码
apt download linux-source-5.13.0 得到linux-source-5.13.0_5.13.0-37.42_all.deb
安装这个deb
dpkg -i linux-source-5.13.0_5.13.0-37.42_all.deb 得到/usr/src/linux-source-5.13.0 tar xvjf linux-source-5.13.0.tar.bz2 cp -rf debian linux-source-5.13.0
二:编译
在内核里面可用看到默认的defconfig arch/x86/configs/x86_64_defconfig
编译defconfig
make x86_64_defconfig
安装编译内核相关的依赖包
apt-get build-dep linux-source-5.13.0
systemtap依赖一些内核选项
CONFIG_DEBUG_FS CONFIG_DEBUG_KERNEL CONFIG_DEBUG_INFO CONFIG_KPROBES
这里修改.config加上即可
直接编译内核即可
make bindeb-pkg -j16
编译完成之后,会在上级目录生成对应的deb文件如下
linux-headers-5.13.19_5.13.19-3_amd64.deb linux-image-5.13.19-dbg_5.13.19-3_amd64.deb linux-image-5.13.19_5.13.19-3_amd64.deb linux-libc-dev_5.13.19-3_amd64.deb
直接安装上述deb即可
重启机器,让系统从新的内核上启动,开机之后,可用uname -a查看内核版本
/boot/vmlinuz -> vmlinuz-5.13.19 uname -a Linux kylin 5.13.19 #3 SMP Tue Apr 19 17:19:44 CST 2022 x86_64 x86_64 x86_64 GNU/Linux
三 编译systemtap
内核准备好了,但是因为内核是5.13.19。而系统中默认安装的systemtap支持不了这么高的内核版本,如果使用ubuntu2004默认提供的systemtap,会报如下错误
fails with vermagic.h:6:2: error: #error "This header can be included from kernel/module.c or *.mod.c only"
所以需要编译新的systemtap
从git拉systemtap的仓库代码
git clone git://sourceware.org/git/systemtap.git
默认使用最新的分支
安装编译的依赖
apt-get build-dep systemtap
编译
./configure make all -j8 make install -j8
编完之后,stap默认安装在local目录
/usr/local/bin/stap --version Systemtap translator/driver (version 4.6/0.176, non-git sources) Copyright (C) 2005-2021 Red Hat, Inc. and others This is free software; see the source for copying conditions. tested kernel versions: 2.6.32 ... 5.15.0-rc7 enabled features: AVAHI BOOST_STRING_REF BPF LIBSQLITE3 NLS NSS
创建软链接
ln -s /usr/local/bin/stap /usr/bin/stap
从上面可用看到,这个stap可以支持最高到5.15.0-rc7的内核版本
四 简单测试
stap -l 'kernel.function("acpi_*")'
上面命令运行之后,会查看到内核的以acpi_开头的所有函数
如果需要使用stp文件进行加载,最简单的hello world如下
probe begin { print ("Hello World\n") exit () }
通过stap命令运行
stap -v hello.stp
能够出现Hello World即可正常
下面测试最简单的内核ko。
编写hello驱动
cat hello.c #include <linux/init.h> #include <linux/module.h> MODULE_LICENSE("Dual BSD/GPL"); static int hello_init(void) { printk(KERN_ALERT "Hello, world\n"); return 0; } static void hello_exit(void) { printk(KERN_ALERT "Goodbye, cruel world\n"); } module_init(hello_init); module_exit(hello_exit);
cat Makefile # If KERNELRELEASE is defined, we've been invoked from the # kernel build system and can use its language. CFLAGS_MODULE += -g ifneq ($(KERNELRELEASE),) obj-m := hello.o # Otherwise we were called directly from the command # line; invoke the kernel build system. else KERNELDIR ?= /lib/modules/$(shell uname -r)/build PWD := $(shell pwd) default: $(MAKE) -C $(KERNELDIR) M=$(PWD) modules endif
make生成hello.ko
将其拷贝到stap识别的目录上
mkdir /usr/lib/modules/`uname -r`/extra/ cp hello.ko /usr/lib/modules/5.13.19/extra/hello.ko
查看stap能否识别到hello.ko
stap -l 'module("hello").function("*")' module("hello").function("hello_exit@/root/ko/hello.c:10") module("hello").function("hello_init@/root/ko/hello.c:5")
编写hello.stp 做简单测试
cat hello.stp #!/usr/bin/stap probe module("hello").function("hello_exit").call { printf("Stap say hello world!\n"); }
先加载ko
insmod /usr/lib/modules/5.13.19/extra/hello.ko
然后加载stap脚本
stap -v hello.stp Pass 1: parsed user script and 481 library scripts using 103440virt/86100res/7488shr/78676data kb, in 420usr/80sys/507real ms. Pass 2: analyzed script: 1 probe, 0 functions, 0 embeds, 0 globals using 105444virt/89108res/8400shr/80680data kb, in 40usr/90sys/123real ms. Pass 3: using cached /root/.systemtap/cache/2a/stap_2a22c74fa0e66004c4e56eb4b264ae1b_1029.c Pass 4: using cached /root/.systemtap/cache/2a/stap_2a22c74fa0e66004c4e56eb4b264ae1b_1029.ko Pass 5: starting run.
看到Pass 5了,说明脚本在监听了
在另一个终端卸载ko驱动 就能监听到hello_exit函数的调用了
rmmod hello 后终端会如下显示 Stap say hello world!
参考链接:
https://wiki.debian.org/BuildADebianKernelPackage
https://wiki.ubuntu.com/Kernel/Systemtap
https://sourceware.org/systemtap/wiki
